Python verifica representatividade de dados em machine learning
São Paulo — InkDesign News — Recentemente, pesquisas em machine learning têm avançado em seu foco em análise de representatividade entre conjuntos de dados, sendo essencial para garantir a eficácia de modelos preditivos.
Arquitetura de modelo
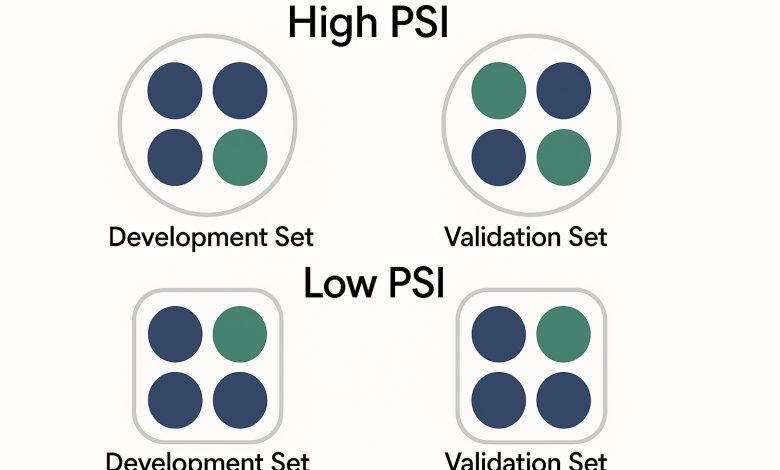
A análise de representatividade é vital em cenários onde um modelo, desenvolvido em um conjunto de dados, é aplicado a um novo. Para verificar isso, disciplinas estatísticas como o Population Stability Index (PSI) e o Cramér’s V têm sido amplamente utilizadas. Ambos os índices ajudam a quantificar diferenças entre distribuições, garantindo que o modelo não se torne obsoleto em condições diferentes.
“A análise de representatividade pode incluir visualizações como histogramas e boxplots, seguidas de testes estatísticos mais rigorosos” (”Representativeness analysis can include visualizations like histograms and boxplots, followed by more rigorous statistical tests”) — Dr. Matteo Courthoud, Especialista em Estatísticas Aplicadas.
Treinamento e otimização
Usando a arquitetura de redes neurais, especificamente abordagens de transfer learning, é possível melhorar a performance em conjuntos de dados mais pequenos. Um exemplo prático é a aplicação do modelo de risco de crédito que precisa ser validado quanto à sua representatividade. Modelos que não são testados adequadamente contra os seus conjuntos de aplicação podem resultar em decisões imprecisas, levando à perda de precisão preditiva.
“Verificar a estruturalidade entre grupos é uma parte essencial do ciclo de vida do modelo” (”Checking structural similarity between groups is an essential part of the model life cycle”) — Ana Sousa, Cientista de Dados, Instituto Tecnológico.
Resultados e métricas
Os resultados obtidos a partir das análises de PSI e Cramér’s V demonstram que, quando esses índices estão abaixo de 0.1, os conjuntos de dados são considerados representativos um do outro. Durante as avaliações, foi observada uma alta correlação entre as distribuições, o que indica um modelo robusto e teoricamente robusto conforme sugerido por métricas de benchmark. Na prática, isso pode se traduzir em uma performance otimizada, garantindo maior confiabilidade nos resultados.
Os passos seguintes incluem a busca por aplicações práticas destas análises, como na verificação de datasets para evitar o fenômeno de overfitting, que pode ser bastante prejudicial em implementações de machine learning.
Fonte: (Towards Data Science – AI, ML & Deep Learning)