Modelos de visão-linguagem aprimoram aprendizado com dados sintéticos
São Paulo — InkDesign News —
A pesquisa recente em machine learning e inteligência artificial (AI) mostra um avanço significativo no entendimento de imagens complexas, essenciais para a operação independente da AI em cenários do dia a dia.
Contexto da pesquisa
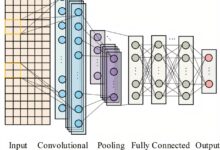
Pesquisadores da Universidade da Pensilvânia e do Allen Institute for AI (Ai2) desenvolveram uma nova abordagem para treinar modelos de AI de código aberto, utilizando dados sintéticos para ensinar sistemas a interpretar informações visuais complexas, como gráficos financeiros e rótulos de nutrição.
Método proposto
O método, denominado CoSyn (síntese guiada por código), utiliza as habilidades de codificação de modelos de AI de código aberto para gerar imagens ricas em texto e criar perguntas e respostas relevantes. Com um conjunto de dados chamado CoSyn-400K, que contém mais de 400 mil imagens sintéticas, o modelo foi treinado para ensinar sistemas a “ver” e entender figuras científicas.
“Isso é como pegar um estudante que é ótimo em escrever e pedir a ele que ensine alguém a desenhar, apenas descrevendo como o desenho deve ser,”
(“This is like taking a student who’s great at writing and asking them to teach someone how to draw, just by describing what the drawing should look like.”)— Yue Yang, Cientista Pesquisador, Ai2
Resultados e impacto
Os modelos treinados com CoSyn superaram sistemas proprietários como o GPT-4V em uma série de sete testes de benchmark. Por exemplo, apenas 7 mil rótulos de nutrição gerados sinteticamente foram suficientes para treinar um modelo que superou competidores treinados com milhões de imagens reais. Além disso, a pesquisa destaca a eficiência na utilização de dados sintéticos, permitindo uma generalização em cenários do mundo real que atendem a necessidades específicas.
“Estamos mostrando que dados sintéticos podem ajudar modelos a generalizar para cenários do mundo real, que podem ser únicos para as necessidades de uma pessoa, como ler um rótulo de nutrição para alguém com baixa visão.”
(“We’re showing that synthetic data can help models generalize to real-world scenarios that could be unique to a person’s needs, like reading a nutrition label for someone with low vision.”)— Mark Yatskar, Professor Assistente, Universidade da Pensilvânia
Os pesquisadores liberaram o código e o dataset CoSyn para o público, convidando a comunidade de pesquisa a construir sobre seu trabalho. Assim, o próximo passo é desenvolver dados sintéticos que capacitem a AI não apenas a entender imagens, mas também a interagir com elas, atuando como agentes digitais inteligentes em tarefas diárias.
Fonte: (TechXplore – Machine Learning & AI)