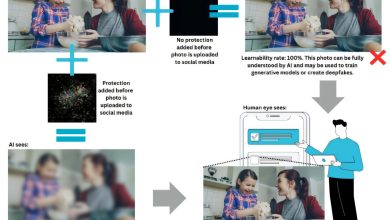
Modelos de AI superam testes, mas desempenho em prática preocupa

São Paulo — InkDesign News —
A pesquisa recente em inteligência artificial (AI) e machine learning trouxe novos desafios para a avaliação do desempenho desses sistemas. Em vez de depender exclusivamente de benchmarks tradicionais, os pesquisadores estão propondo uma abordagem mais holística e contextualizada para medir a eficácia e o impacto dessas tecnologias no mundo real.
Contexto da pesquisa
O crescente uso de AI em diversas áreas, como saúde, educação e segurança, exige métodos de avaliação que vão além dos testes de desempenho convencionais. Especialistas da área, incluindo metrologistas, sugerem que a maneira como avaliamos esses sistemas precisa evoluir para refletir suas aplicações reais.
Método proposto
Os pesquisadores sugerem uma arquitetura avaliativa que combina técnicas de aprendizado de máquina, como Modelos de Linguagem de Grande Escala (LLMs) e Redes Neurais Convolucionais (CNNs), para realizar testes mais abrangentes. A iniciativa busca integrar diferentes métodos de avaliação que considerem as condições e contextos de implementação de cada sistema.
“Essas novas estruturas visam capturar a complexidade das interações entre humanos e AI” (“These new frameworks aim to capture the complexity of interactions between humans and AI.”)
— Rumman Chowdhury, Especialista em Ética Algorítmica
Resultados e impacto
Até o momento, os modelos estão sendo testados em bases de dados diversificadas, utilizando métricas que vão além da precisão simples, como a relevância das respostas em situações do mundo real. Além disso, a pesquisa destaca a importância de métodos como o red-teaming, que avalia vulnerabilidades ao tentar induzir resultados indesejados deliberadamente.
Embora ainda em fase de desenvolvimento, esses métodos prometem melhorar significativamente a confiabilidade das aplicações de AI, impactando positivamente áreas críticas, como diagnósticos médicos e gestão pública.
Os desafios futuros incluem a implementação desses métodos em larga escala e a garantia de que as avaliações sejam rigorosas e reprodutíveis, com vistas a proteger os interesses da sociedade como um todo.
Fonte: (TechXplore – Machine Learning & AI)