Modelos de AI avaliam classificação de textos com nova técnica
São Paulo — InkDesign News —
A recente pesquisa do laboratório de Sistemas de Informação e Decisão do MIT (LIDS) traz avanços significativos em machine learning e inteligência artificial, focando na acurácia de classificadores de texto que avaliam informações automatizadas.
Contexto da pesquisa
Classificadores de texto desempenham um papel central na análise automática de conteúdos, como resenhas de filmes, notícias e interações em chatbots. O desafio, contudo, é garantir a precisão dessas classificações, principalmente em contextos críticos, como informações financeiras ou médicas.
Método proposto
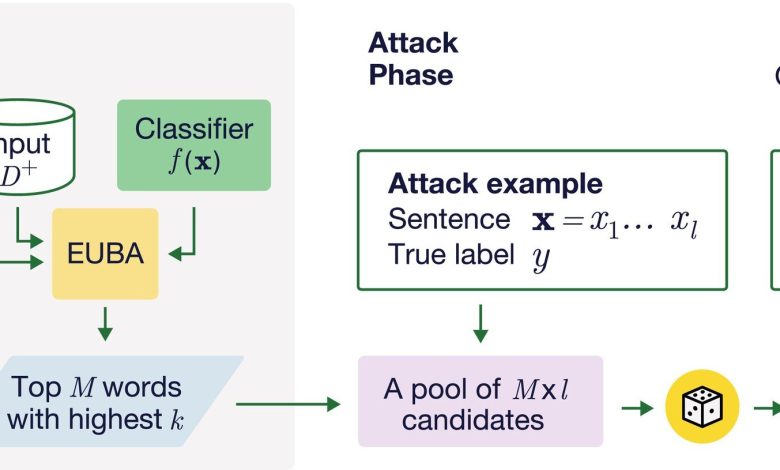
A equipe liderada por Kalyan Veeramachaneni desenvolveu um software que combina a utilização de exemplos adversariais e modelos de linguagem grande (LLMs) para testar e melhorar a acurácia dos classificadores. O software, conhecido como SP-Attack, gera sentenças adversariais que podem enganar o classificador. Isso é feito ao modificar palavras específicas que, embora mantenham o significado, alteram a classificação.
“A mudança de apenas uma palavra é frequentemente suficiente para enganar o classificador”
(“Most of the time, this was just a one-word change.”)— Kalyan Veeramachaneni, Pesquisador Principal, MIT
O modelo analisa um vocabulário de 30.000 palavras, identificando que apenas 0,1% delas pode causar quase metade das reversões de classificação observadas. Essa abordagem permite um teste mais focado e eficiente dos classificadores.
Resultados e impacto
Os testes demonstraram que, ao empregar o novo método, a taxa de sucesso em ataques adversariais caiu de 66% para 33,7%, mostrando um aumento na robustez dos classificadores. Além disso, o software está disponível livremente para utilização, beneficiando a comunidade de pesquisa e empresas que dependem de interações automatizadas.
“Melhorar a acurácia pode parecer irrelevante em contextos simples, mas é crucial para evitar a divulgação de informações sensíveis”
(“Making classifiers more accurate may not sound like a big deal…but increasingly, classifiers are being used in settings where the outcomes really do matter.”)— Kalyan Veeramachaneni, Pesquisador Principal, MIT
As implicações dessa pesquisa abrangem desde a minimização de riscos legais em interações automatizadas até a melhoria em aplicações na área da saúde e ciência, onde decisões erradas podem ter consequências sérias.
Fonte: (TechXplore – Machine Learning & AI)