São Paulo — InkDesign News —
Pesquisadores do MIT analisaram como modelos de machine learning, especialmente os baseados em transformadores, rastreiam mudanças em sequências, revelando que seus métodos de previsão podem ser otimizados através de técnicas matemáticas inovadoras.
Contexto da pesquisa
Estudos sobre inteligência artificial (IA) frequentemente se deparam com a questão da previsibilidade em tarefas dinâmicas, como a previsão do clima ou a evolução de narrativas. No entanto, a maneira como esses modelos realmente processam informações em tempo real permanecia parcialmente obscura. A pesquisa foi realizada no Laboratório de Ciência da Computação e Inteligência Artificial (CSAIL) do MIT.
Método proposto
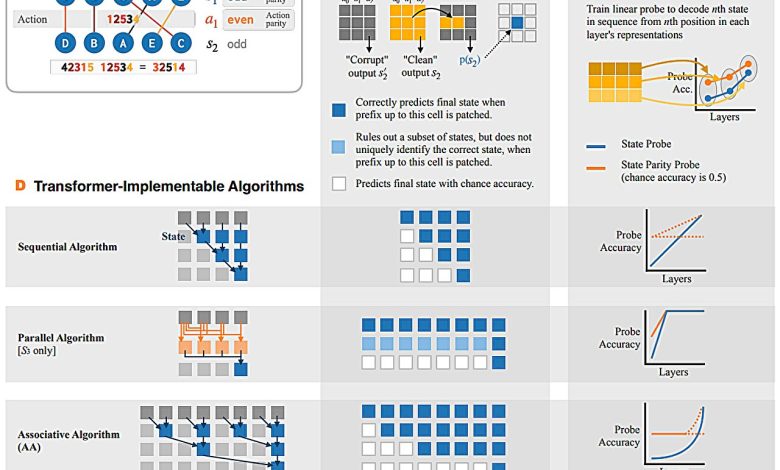
A equipe conduziu testes que simulam jogos de concentração, onde modelos previam a disposição final de dígitos após serem embaralhados. Foram observados dois padrões principais: o “Algoritmo Associativo”, que agrupa etapas adjacentes e calcula a previsão final, e o “Algoritmo Paridade-Associativa”, que determina se a disposição final resulta de um número par ou ímpar de rearranjos. Ambas as abordagens demonstraram uma estrutura hierárquica semelhante a uma árvore, permitindo um agrupamento eficiente das informações.
“Esses comportamentos nos dizem que os transformadores realizam simulações por meio de varredura associativa. Em vez de seguir as mudanças de estado passo a passo, os modelos organizam-nas em hierarquias.”
(“These behaviors tell us that transformers perform simulation by associative scan. Instead of following state changes step-by-step, the models organize them into hierarchies.”)— Belinda Li, Ph.D. Student, CSAIL
Resultados e impacto
Os modelos mostraram um desempenho superior com o Algoritmo Associativo em experimentos longos, sugerindo que uma abordagem mais adaptativa poderia melhorar significativamente a precisão nas previsões. A utilização de contatos como “probing” e “activation patching” permitiu uma melhor compreensão dos erros e das adaptações dos modelos durante os testes. Apesar das limitações do experimento inicial considerando modelos de pequeno porte e dados sintéticos, a pesquisa sugere que resultados semelhantes ocorreriam em modelos maiores, como o GPT-4.1.
“Encontramos que, quando os modelos de linguagem usam uma heurística logo no início do treinamento, eles começam a construir truques dentro de seus mecanismos.”
(“We’ve found that when language models use a heuristic early on in training, they’ll start to build these tricks into their mechanisms.”)— Belinda Li, Ph.D. Student, CSAIL
A pesquisa abre portas para melhorias significativas em como modelos de IA lidam com tarefas que exigem rastreamento de estados, indicando que ajustes nas formas de apresentar dados durante o treinamento podem promover um aprendizado mais sólido e eficaz.
Fonte: (TechXplore – Machine Learning & AI)