Recentemente, pesquisadores desenvolveram um método inovador para preservar a segurança em modelos de AI mesmo quando estes são reduzidos para operar em dispositivos de baixo consumo, como smartphones e veículos.
Contexto da pesquisa
Pesquisadores da Universidade da Califórnia, Riverside, abordaram o desafio das vulnerabilidades em modelos de código aberto em machine learning ao serem podados para eficiência. Modelos como esses, que podem ser baixados e executados offline, têm a vantagem da transparência, mas também uma maior suscetibilidade a abusos devido à ausência de supervisão contínua.
Método proposto
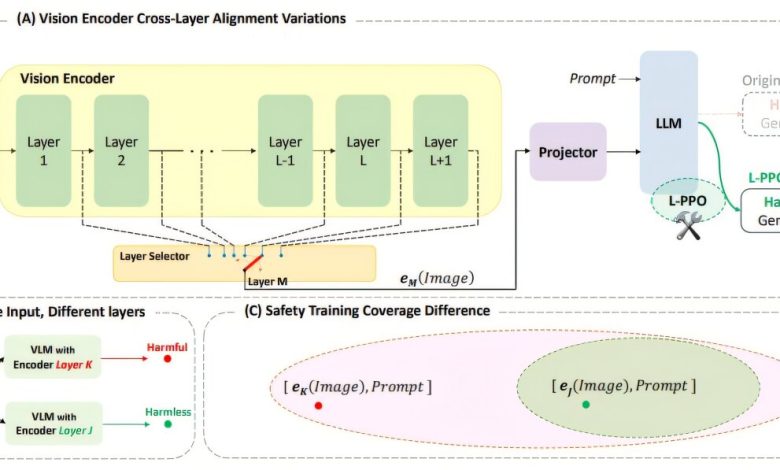
A equipe focou na preservação das características de segurança essenciais, que frequentemente se perdem quando as camadas internas são puladas para economizar recursos. O modelo de linguagem-visual LLaVA 1.5 foi o foco da pesquisa, onde combinações específicas de imagens e perguntas prejudiciais demonstraram contornar filtros de segurança.
“Algumas das camadas puladas se mostraram essenciais para prevenir respostas inseguras.”
(“Some of the skipped layers turn out to be essential for preventing unsafe outputs.”)— Amit Roy-Chowdhury, Professor, Universidade da Califórnia, Riverside
Resultados e impacto
Após o re-treinamento, o modelo reagiu de maneira segura a consultas perigosas, mesmo funcionando com apenas uma fração de sua arquitetura original, provando a eficácia da técnica. Essa abordagem não depende de filtros externos, mas sim transforma a compreensão interna do modelo sobre conteúdos arriscados.
“Não se trata de adicionar filtros ou guardrails externos; estamos mudando o entendimento interno do modelo, para que ele esteja em ‘bom comportamento’ por padrão.”
(“This isn’t about adding filters or external guardrails; we’re changing the model’s internal understanding, so it’s on good behavior by default.”)— Saketh Bachu, Estudante de Pós-Graduação, Universidade da Califórnia, Riverside
O trabalho busca garantir que a segurança se mantenha em todas as camadas internas de modelos de AI, estabelecendo uma base robusta para aplicações em condições do mundo real. As próximas etapas incluem o desenvolvimento de técnicas que assegurem a integridade de todos os aspectos da AI em cenários variados.
Fonte: (TechXplore – Machine Learning & AI)