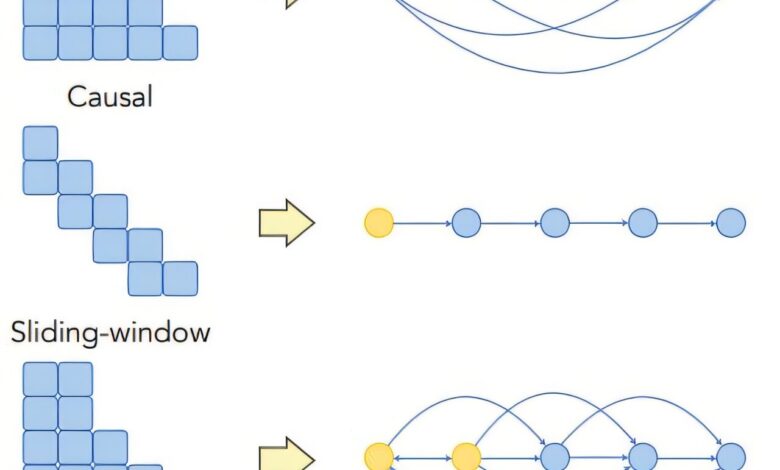
Pesquisas recentes em machine learning destacam uma tendência preocupante em modelos de linguagem, indicando que a arquitetura dessas inteligências artificiais pode favorecer informações posicionadas no início e no final dos documentos, negligenciando o conteúdo médio.
Contexto da pesquisa
Um estudo conduzido por pesquisadores do MIT revelou uma tendência chamada “posição bias”, que afeta modelos de linguagem de grande escala (LLMs). Esta viés pode influenciar significativamente a eficácia de assistentes virtuais na recuperação de informações em documentos extensos, como afidavit, onde as informações relevantes podem ser facilmente perdidas se estiverem situadas em partes intermediárias do texto.
Método proposto
Os pesquisadores desenvolveram uma estrutura teórica que examina como informações fluem dentro da arquitetura de machine learning dos LLMs. Eles identificaram que decisões de design, especialmente aquelas que afetam a disseminação de informações entre as palavras de entrada, podem intensificar o viés de posição.
“Esses modelos são caixas-pretas, então, como um usuário de LLM, você provavelmente não sabe que o viés de posição pode causar inconsistências em seu modelo.”
(“These models are black boxes, so as an LLM user, you probably don’t know that position bias can cause your model to be inconsistent.”)— Xinyi Wu, Estudante de Graduação, MIT
Resultados e impacto
Os experimentos revelaram que a precisão das recuperações de informações apresenta um padrão U, onde o desempenho é ideal quando o texto certo está localizado no início ou no final do documento, mas cai acentuadamente quando o texto está no meio. O trabalho sugere que ajustes nas técnicas de mascaramento de atenção e na aplicação de codificações posicionais podem ajudar a atenuar este viés, aumentando a precisão destes modelos em aplicações práticas.
“Se você sabe que seus dados estão enviesados de determinada maneira, deve ajustar seu modelo além de suas escolhas de modelagem.”
(“If you know your data is biased in a certain way, then you should also finetune your model on top of adjusting your modeling choices.”)— Xinyi Wu, Estudante de Graduação, MIT
Os pesquisadores apontam que futuras investigações podem focar nas codificações posicionais e em como explorar o viés de posição em determinadas aplicações. Isso poderá levar à criação de chatbots mais confiáveis e sistemas de IA que respondem de maneira mais justa a conjuntos de dados complexos.
Fonte: (TechXplore – Machine Learning & AI)