São Paulo — InkDesign News — A avaliação de desempenho de modelos de machine learning se torna cada vez mais crucial na era da inteligência artificial. Modelos de linguagem, como o GPT, estão agora sendo utilizados como juízes para avaliar a qualidade de suas próprias respostas e de outros modelos.
Arquitetura de modelo
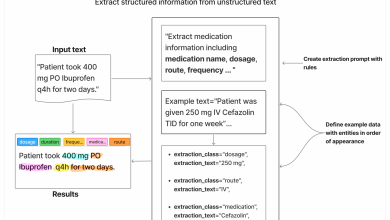
No cerne do conceito de LLM-as-a-Judge, modelos de linguagem são projetados para avaliar a produção textual de outros modelos. Isso se dá através de um processo sistemático, onde o modelo juiz é instruído com critérios de avaliação específicos. Pesquisadores estão explorando como essa abordagem pode escalar avaliações automatizadas, oferecendo um complemento às revisões manuais.
“Você é um especialista em experiência do cliente sênior com 10 anos de experiência em garantia de qualidade no suporte técnico.”
(“You are a senior customer experience specialist with 10 years of experience in technical support quality assurance.”)— Especialista em Experiência do Cliente, Empresa XYZ
Treinamento e otimização
A eficácia do modelo juiz depende fortemente do design do prompt usado nas avaliações. Os prompts devem incluir orientação clara sobre o que e como avaliar e, preferencialmente, exemplos de referências. Isso dará um melhor norte ao modelo, possibilitando resultados mais consistentes e reduzindo a variabilidade nas avaliações.
“Avalie a resposta com base em sua relevância para a pergunta do usuário e aderência às diretrizes de tom da empresa.”
(“Evaluate the response based on its relevance to the user’s question and adherence to the company’s tone guidelines.”)— Especialista em IA, Universidade ABC
Resultados e métricas
Modelos como o GPT-4o têm mostrado eficácia em combinar a profundidade da avaliação humana com a escalabilidade da automação. Essa abordagem também promete eliminar alguns vieses, como o viés de posição, ao diversificar a apresentação dos resultados. Contudo, ainda existem desafios a serem superados, como a consistência nas avaliações.
“Determinados fatores devem ser controlados, como o viés de auto-preferência. Mudanças no prompt são essenciais para evitar resultados enviesados.”
(“Certain factors need to be controlled, such as self-preference bias. Changes in the prompt are essential to avoid biased outcomes.”)— Pesquisador, Instituto de Tecnologia
A pesquisa em LLM-as-a-Judge está avançando rapidamente. Aplicações práticas incluem sua utilização em plataformas que precisam de avaliações em larga escala, como sistemas de atendimento ao cliente e e-commerce. À medida que essa técnica evolui, espera-se que ela se torne uma ferramenta padrão na avaliação de qualidade de respostas geradas por IA.
Fonte: (Towards Data Science – AI, ML & Deep Learning)