LangExtract transforma anotações clínicas em dados estruturados
São Paulo — InkDesign News —
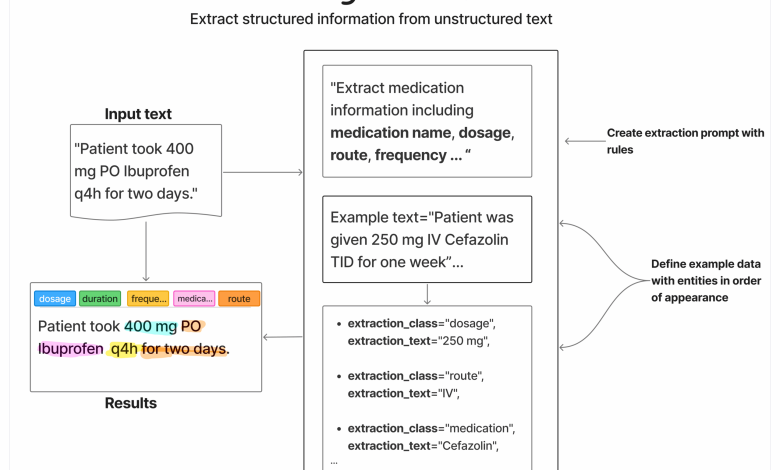
Recentes inovações em machine learning têm impulsionado a extração de informações em áreas críticas, como a saúde. Uma nova biblioteca chamada LangExtract, desenvolvida por engenheiros do Google, aplica deep learning para transformar textos não estruturados, como anotações clínicas, em dados estruturados.
Arquitetura de modelo
LangExtract se destaca por seu uso de Modelos de Linguagem de Grande Escala (LLMs), oferecendo facilidade na definição de tarefas de extração. Os usuários especificam o que desejam extrair através de prompts escritos, complementados por exemplos de exemplo de alta qualidade para guiar o modelo. Essa abordagem é essencial para obter resultados precisos em contextos complexos, como notas médicas.
“Para cada reação adversa, inclua sua gravidade como um atributo se mencionada. Utilize trechos de texto exatos do original.”
(“For each adverse reaction, include its severity as an attribute if mentioned. Use exact text spans from the original text.”)— Autor, LangExtract
A integração com o modelo Gemini 2.5 Flash é um diferencial, permitindo análises mais robustas. Os fluxos de trabalho são simples, compostos por três etapas principais: definição da tarefa, fornecimento de exemplos e execução da extração. O modelo pode ser treinado com conjuntos de dados como o ADE Corpus v2 para melhorar consideravelmente a acurácia.
Treinamento e otimização
A instalação da biblioteca é feita via comando pip, especificamente na criação de ambientes virtuais. A utilização de múltiplas passagens sobre o texto, combinada com execução paralela e divisões de textos longos, aumenta a eficácia do modelo. A utilização de parâmetros como extraction_passes e max_workers otimiza o desempenho ao lidar com documentos extensos.
“LangExtract pode identificar corretamente reações adversas, sem confundi-las com condições pré-existentes do paciente.”
(“LangExtract correctly identifies the adverse drug reaction without confusing it with the patient’s pre-existing conditions.”)— Autor, LangExtract
Esse processo resulta em uma ferramenta poderosa que não só detecta medicamentos e dosagens, mas também ações tomadas em resposta a reações adversas, sendo crucial para garantir a segurança do paciente durante tratamentos médicos.
Resultados e métricas
Os experimentos realizados mostraram que LangExtract é eficaz na extração de adverse drug reactions (ADRs) em notas clínicas. Embora tenha apresentado resultados encorajadores, a biblioteca ainda depende da qualidade dos exemplos fornecidos pelos usuários para alcançar uma performance ideal.
A análise mostrou que a precisão na detecção de ADRs é crítica, mas mais testes rigorosos são necessários para uma aplicação em produção. Com a segurança do paciente em mente, é evidente que ferramentas como LangExtract são essenciais para aprimorar a vigilância farmacológica.
A aplicação prática de LangExtract poderá revolucionar a forma como dados clínicos são processados, e seu potencial de uso local, através do Ollama, é uma aproximação significativa para proteger dados sensíveis no setor de saúde. Pesquisas futuras devem focar na validação em conjuntos de dados mais amplos e variados para garantir a robustez e a confiabilidade da tecnologia.
Fonte: (Towards Data Science – AI, ML & Deep Learning)