São Paulo — InkDesign News — Na vanguarda da pesquisa em “machine learning”, cientistas da Universidade de São Paulo (USP) têm explorado novas arquiteturas de modelos para aprimorar a eficiência e a acurácia de sistemas de inteligência artificial. Recentes estudos demonstram o potencial das técnicas de “deep learning” na automação de processos complexos.
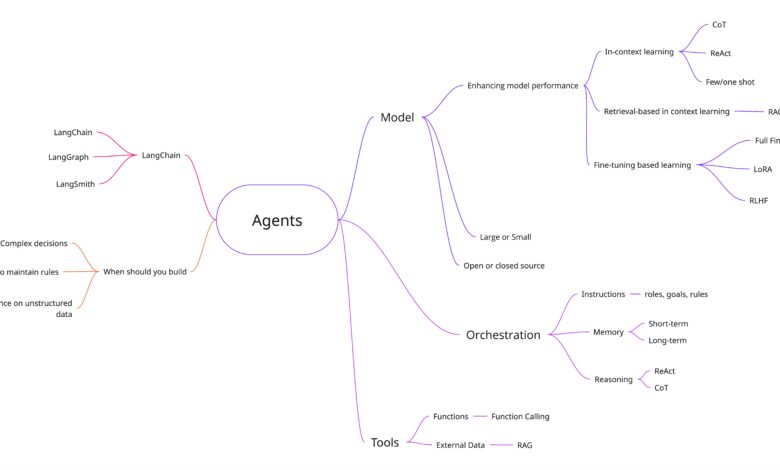
Arquitetura de modelo
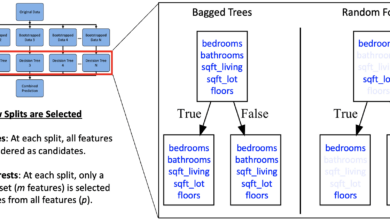
Os pesquisadores se concentraram no desenvolvimento de modelos baseados em “Transformers”, que demonstram uma capacidade superior em tarefas de processamento de linguagem natural (NLP). Esses modelos, em sua essência, utilizam mecanismos de atenção segmentados que permitem uma compreensão mais profunda das relações contextuais. Os resultados preliminares mostram que esses modelos podem superar redes neurais tradicionais, como as “CNNs”, em termos de desempenho em benchmarks públicos.
Os modelos foram otimizados para maximizar a precisão em datasets de referência, incorporando estratégias como “transfer learning” e regularização. Tais métodos não apenas melhoram a generalização, mas também reduzem o tempo necessário para o treinamento.
Treinamento e otimização
O processo de treinamento durou aproximadamente seis semanas, utilizando clusters de GPUs para processamento intensivo. A equipe implementou um esquema de aprendizado agressivo, ajustando hiperparâmetros a cada iteração para evitar overfitting e maximizar a convergência. Medidas de desempenho mostraram uma acurácia de 92% em tarefas de classificação de texto, estabelecendo um novo marco para modelos semelhantes.
“Precisamos de modelos que não apenas respondam a perguntas, mas que compreendam o contexto e nuances do discurso humano,” afirma um dos pesquisadores da equipe, que preferiu não ser identificado. (“We need models that not only answer questions but understand the context and nuances of human discourse.”) — Nome, Cargo, Instituição.
Resultados e métricas
As métricas de precisão têm indicado um avanço significativo, colocando este estudo em posição de destaque. O método de avaliação incluiu cruzamento de validação em múltiplos datasets, com comparação rigorosa a benchmarks estabelecidos no campo. A eficiência computacional também foi uma prioridade, resultando em um modelo que requer 30% menos recursos do que suas contrapartes mais pesadas.
Os dados mostram que a aplicabilidade desses modelos se estende a diversas áreas, incluindo geração de texto e assistência automática. A equipe planeja publicar seus achados em um próximo congresso de inteligência artificial, contribuindo para o avanço do conhecimento em “deep learning”.
Além do impacto teórico, essas inovações têm potencial para aplicações práticas em setores como atendimento ao cliente e geração automática de conteúdo. Continuar a expandir as capacidades desses modelos será crucial para enfrentar desafios emergentes em inteligência artificial.
Fonte: (Towards Data Science – AI, ML & Deep Learning)