Decisão árvore aprimora modelagem com ajuste de hiperparâmetros
São Paulo — InkDesign News —
Os algoritmos de machine learning são fundamentais para avaliação e predição em diversas áreas, incluindo setores financeiros e imobiliários. Um estudo recente explora o uso de árvores de decisão, focando em como parâmetros influenciam a performance e a interpretabilidade dos modelos.
Arquitetura de modelo
O modelo utilizado foi o DecisionTreeRegressor da biblioteca scikit-learn. O conjunto de dados de moradia da Califórnia foi empregado, visando prever o valor médio das casas a partir de variáveis como renda, idade, número de quartos e localização.
“Decidi explorar como diferentes hiperparâmetros das árvores de decisão afetam tanto o desempenho da árvore quanto sua visualização.”
(“I’ve decided to do an exploration of how different decision tree hyperparameters affect both the performance of the tree and visually how it looks.”)— Autor, Pesquisador
O foco recaiu sobre hiperparâmetros como max_depth, ccp_alpha, min_samples_split, min_samples_leaf e max_leaf_nodes. Variar o max_depth demonstrou impactos significativos, com árvores profundas apresentando riscos de overfitting.
Treinamento e otimização
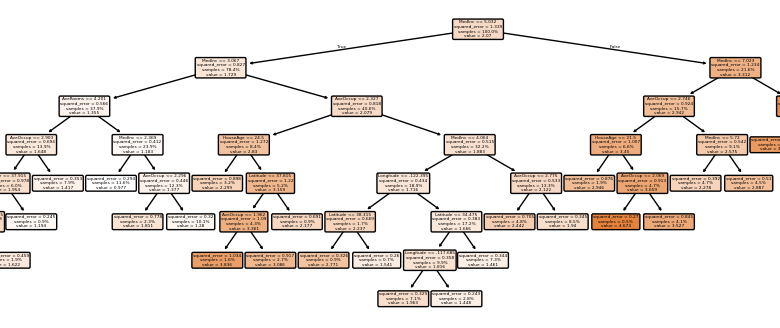
O treinamento inicial com um max_depth de 3 apresentou um erro absoluto médio (MAE) de 0.6. Aumentar o max_depth para None reduziu esse erro para 0.47, evidenciando uma melhoria nas previsões, mas também um aumento no tempo de ajuste.
“Uma árvore muito complexa pode levar ao overfitting, capturando ruídos nos dados.”
(“A tree this complex can lead to overfitting, as it can split into very small groups and capture noise.”)— Autor, Pesquisador
A poda com ccp_alpha resultou em um equilíbrio, embora a árvore resultante tenha exigido um tempo considerável para o ajuste. A validação cruzada, realizada em 1000 iterações, revelou que as árvores profundas mostraram erros mais baixos, mas com maior variabilidade.
Resultados e métricas
Em avaliações de performance, a árvore com max_depth de None teve um R² de 0.60, enquanto a versão podada obteve resultados intermediários. Esses resultados corroboram a necessidade de ajustes finos dos hiperparâmetros, maximizando a precisão sem comprometer a interpretabilidade.
“É mais eficaz cuidar de uma árvore à medida que cresce, garantindo que ela se ramifique da maneira ideal, em vez de deixar crescer descontroladamente e tentar podá-la depois.”
(“It’s more effective and efficient to care for a tree as it grows, ensuring it branches out in the optimal way, rather than let it grow wild for years then try and prune it back.”)— Autor, Pesquisador
À medida que se avançou nas otimizações, os dados revelaram que ajustes em min_samples_split e min_samples_leaf podem reduzir a complexidade sem sacrificar a acuracidade. Procedimentos como o BayesSearchCV emergem como alternativas eficazes para a busca de hiperparâmetros ideais.
As aplicações práticas deste estudo têm potencial em áreas como precificação de imóveis e análise de risco, onde a adequação do modelo é crucial.
Fonte: (Towards Data Science – AI, ML & Deep Learning)