Contexto da pesquisa
A pesquisa em machine learning (ML) tem avançado rapidamente, mas o desafio de otimizar a exploração em ambientes complexos, como a robótica e jogos, permanece. A busca por métodos que incentivem a aprendizagem eficiente e economizem tempo é cada vez mais crítica.
Método proposto
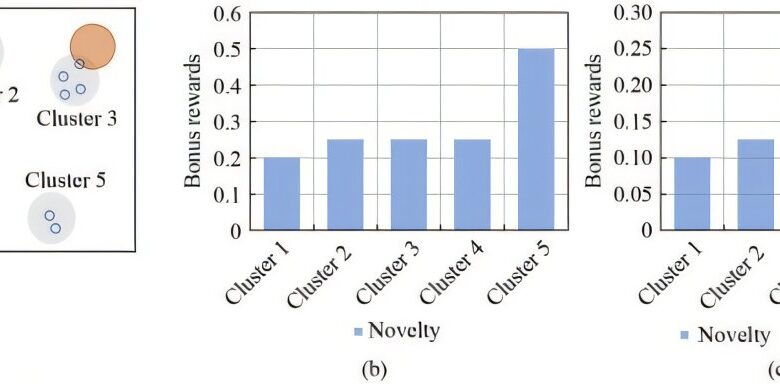
Pesquisadores da Universidade de Nanjing e da UC Berkeley desenvolveram uma abordagem chamada aprendizado por reforço agrupado (CRL), que utiliza a técnica de K-means para classificar estados semelhantes em “clusters”. Isso permite que a AI receba recompensas não só por novidades, mas também pela qualidade das experiências acumuladas. O método considera a frequência de visitas a cada cluster (novidade) e a qualidade dos resultados obtidos, proporcionando um sistema de recompensas mais equilibrado e eficiente.
“Ao agrupar experiências e equilibrar curiosidade com sucesso comprovado, oferecemos à AI uma maneira mais humana de aprender.”
(“By grouping experiences and balancing curiosity with proven success, we’ve given AI a more human-like way to learn.”)— Prof. Wu-Jun Li, Pesquisador Principal, Universidade de Nanjing
Resultados e impacto
Os resultados mostraram que o CRL supera métodos tradicionais em múltiplos benchmarks, incluindo tarefas de controle robótico e jogos desafiadores da Atari. A abordagem possibilitou um aprendizado mais rápido e com menos erros, destacando-se pela sua aplicabilidade em domínios críticos, como condução autônoma, otimização energética e programação inteligente.
O CRL pode ser facilmente integrado a sistemas de AI existentes, o que o torna promissor para um futuro em que máquinas inteligentes desempenham papéis cada vez mais importantes em nossas vidas.
Fonte: (TechXplore – Machine Learning & AI)

































