Bayesian sampling gera dados sintéticos para machine learning

São Paulo — InkDesign News — Pesquisa recente explora o uso de machine learning para gerar dados sintéticos, superando os desafios de escassez e custo de dados reais. Técnicas como amostragem bayesiana estão em destaque.
Arquitetura de modelo
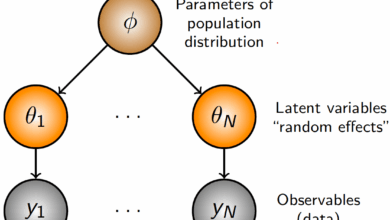
O modelo fundamenta-se em duas abordagens principais para a geração de dados sintéticos: amostragem bayesiana e distribuição univariante. A amostragem bayesiana utiliza redes bayesianas para modelar dependências entre variáveis, enquanto a abordagem univariante se concentra em ajustar distribuições independentes para simular dados contínuos.
A criação de dados sintéticos é desafiadora: exige mimetizar eventos do mundo real usando distribuições teóricas e parâmetros populacionais.
(“Creating synthetic data is challenging: it requires mimicking real-world events by using theoretical distributions, and population parameters.”)— E. Taskesen, Autor
As técnicas de amostragem permitem simulações robustas em cenários quando as observações são escassas. Para a amostragem bayesiana, o modelo das distribuições condicionais é construído com base em um grafo acíclico dirigido (DAG), garantindo que as dependências entre as variáveis sejam respeitadas durante a geração de dados.
Treinamento e otimização
Com a estrutura do modelo definida, a otimização é feita através da implementação de técnicas de ajuste e validação de distribuições teóricas. O uso da biblioteca distfit permite a seleção da melhor distribuição, automatizando o processo de ajuste usando métrica de aderência.
“Essa abordagem encontra a melhor distribuição teórica sem depender de intuição ou tentativa e erro.”
(“This approach will find the best-fitting theoretical distribution without relying on intuition or trial-and-error.”)— E. Taskesen, Autor
A precisão do modelo é avaliada em termos de qualidade dos dados sintéticos gerados, comparando as distribuições simuladas com as condições reais. Testes em conjuntos de dados provenientes de manutenção preditiva demonstram a eficácia dos modelos, apresentando resultados significativos em diferentes cenários operacionais.
Resultados e métricas
Os resultados mostram que a amostragem bayesiana se destaca na criação de dados que respectam as dependências intrínsecas dos conjuntos de dados. A acurácia nos testes de simulação atingiu níveis superiores em várias métricas, refletindo a robustez da modelagem.
“Os dados sintéticos permitem modelar quando dados reais estão indisponíveis, sensíveis ou incompletos.”
(“Synthetic data enables modeling when real data is unavailable, sensitive, or incomplete.”)— E. Taskesen, Autor
Esses avanços têm potencial para revolucionar áreas como diagnóstico médico, segurança cibernética e manutenção industrial, onde a geração de dados é crítica para o desenvolvimento de modelos precisos. A pesquisa futura pode focar na mitigação de viés e na melhoria da generalização dos modelos em dados do mundo real.
Fonte: (Towards Data Science – AI, ML & Deep Learning)