São Paulo — InkDesign News —
A pesquisa em machine learning avança com novas técnicas que aumentam a transparência e a eficácia na interpretação de imagens. Um novo modelo desenvolvido na Universidade de Princeton promete melhorias significativas em aplicações que vão desde a direção autônoma até a robótica.
Contexto da pesquisa
Nos últimos anos, cientistas da computação têm se debruçado sobre ferramentas computacionais que analisam e interpretam imagens, levando a avanços significativos em áreas como robótica e saúde. Entretanto, muitos dos modelos atuais baseados em redes neurais feed-forward mostram limitações na generalização para novos dados.
Método proposto
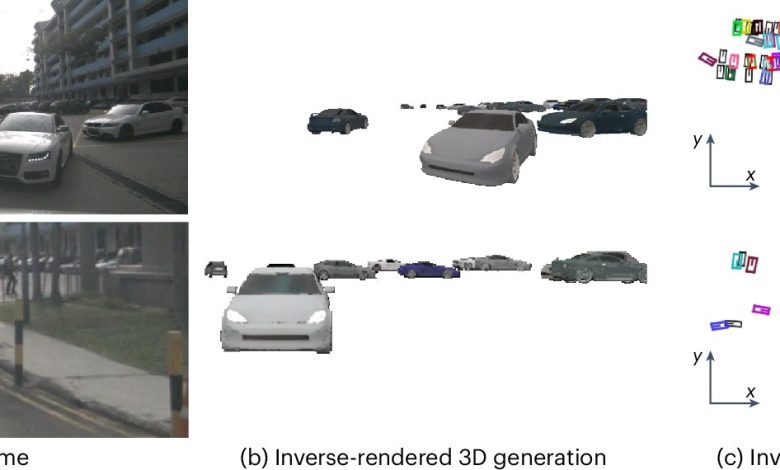
Os pesquisadores introduziram uma abordagem de renderização inversa que utiliza uma chamada “pipeline de renderização diferenciável”. Este método permite simular a criação de imagens com base em representações comprimidas geradas por modelos de inteligência artificial. Como explica Felix Heide, autor sênior do estudo, “desenvolvemos uma abordagem de análise por síntese que nos permite resolver tarefas de visão, como rastreamento, como problemas de otimização em tempo de teste” (
“We developed an analysis-by-synthesis approach that allows us to solve vision tasks, such as tracking, as test-time optimization problems.”
(“Desenvolvemos uma abordagem de análise por síntese que nos permite resolver tarefas de visão, como rastreamento, como problemas de otimização em tempo de teste.”)— Felix Heide, Autor Sênior, Universidade de Princeton
).
O modelo se destaca pela sua capacidade de não precisar ser treinado em novos conjuntos de dados, generalizando com sucesso através de múltiplos benchmarks, como o nuScenes e o Waymo Open Dataset.
Resultados e impacto
Os resultados demonstram que a abordagem proposta não só rivaliza com métodos tradicionais de aprendizado supervisionado em termos de precisão, mas também fornece explicações explícitas das 3D vistas. Os pesquisadores observaram que a representação e rastreamento de objetos 3D funcionaram de forma eficaz, entregando resultados consistentes sem necessidade de ajustes manuais.
Além disso, a técnica apresenta um significativo potencial para reduzir os custos de ajuste fino em novos dados, promovendo de forma eficiente um pipeline de automação de rotulagem. Em uma declaração final, Heide comentou sobre as possibilidades futuras, mencionando que “a lógica é expandir a abordagem para outras tarefas de percepção, como detecção e segmentação 3D” (
“A logical next step is the expansion of the proposed approach to other perception tasks, such as 3D detection and 3D segmentation.”
(“A lógica é expandir a abordagem proposta para outras tarefas de percepção, como detecção e segmentação 3D.”)— Felix Heide, Autor Sênior, Universidade de Princeton
).
Essa pesquisa pode transformar a forma como aplicações de visão computacional são desenvolvidas, aumentando a eficácia e a transparência dos modelos de AI. Os próximos passos incluem testar a tecnologia em uma variedade maior de tarefas de visão computacional.
Fonte: (TechXplore – Machine Learning & AI)