São Paulo — InkDesign News — O uso de machine learning para medir similaridades semânticas, como a métrica de similaridade cosseno, tem sido um foco crescente em aplicações de processamento de linguagem natural (NLP). Este método é fundamental para a análise de textos, permitindo comparações efetivas entre documentos.
Arquitetura de modelo
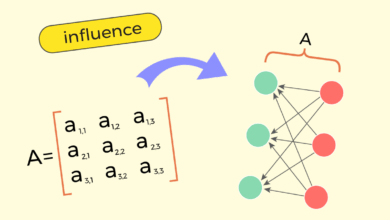
A métrica de similaridade cosseno é fundamentada na função cosseno, que relaciona-se com a definição de ângulos em um espaço vetorial. Em termos práticos, a similaridade entre vetores de texto é expressa através do cálculo do produto escalar dividido pelo produto de suas magnitudes. Essa característica a torna menos suscetível a variações de magnitude entre os vetores em comparação com a distância euclidiana.
“A métrica de similaridade cosseno captura o comportamento de sobreposição semântica e polaridade semântica.”
(“The cosine similarity metric captures the interplay of semantic overlap and semantic polarity.”)— Autor Desconhecido, Pesquisa
O uso de modelos pré-treinados, como o MiniLM, facilita a geração de embeddings que respeitam essa teoria, permitindo que a análise de palavras como “filme” e “música” resulte em uma similaridade elevada.
Treinamento e otimização
A implementação prática da similaridade cosseno envolve a aplicação de programação em Python, que calcula a similaridade de maneira direta. Ao contrário da distância euclidiana, que pode ser afetada por variações em magnitudes, a similaridade cosseno é focada no ângulo formador entre os vetores; o que a torna uma escolha preferida em muitas análises de NLP.
“A similaridade cosseno deve se aproximar de 1 se os vetores apontarem na mesma direção.”
(“Cosine similarity should be close to 1 if the vectors point in the same direction.”)— Autor Desconhecido, Pesquisa
Portanto, ao modelar palavras que expressam sentimentos opostos como “bom” e “ruim”, a similaridade cosseno pode oferecer dados valiosos sobre a polaridade das interpretações.
Resultados e métricas
A comparação entre diferentes modelos de embeddings revela que palavras sinônimas, como “filme” e “cinema”, produzem uma similaridade significativa. Em contrapartida, termos antônimos como “bom” e “ruim” retornam valores negativos quando são analisados por modelos que conseguem codificar a polaridade semântica.
“As palavras ‘filme’ e ‘cinema’ têm alta similaridade, enquanto ‘bom’ e ‘ruim’ apresentam um resultado negativo.”
(“The words ‘movie’ and ‘film’ have high similarity, while ‘good’ and ‘bad’ show a negative result.”)— Autor Desconhecido, Pesquisa
Estas observações enfatizam a necessidade de coesão entre o modelo de embedding e a tarefa proposta, uma vez que a técnica escolhida impacta significativamente nos resultados finais.
As aplicações práticas da similaridade cosseno vão além da simples comparação lexical, constituindo-se numa ferramenta essencial em sistemas de recomendação e análise de sentimentos. Pesquisas futuras poderão se aprofundar em modelos que não apenas identificam similaridades, mas também integram relações complexas de polaridade em textos.
Fonte: (Towards Data Science – AI, ML & Deep Learning)