Contexto da pesquisa
A pesquisa em machine learning avança rapidamente, especialmente no domínio dos modelos de linguagem de grande escala (LLMs). Recentemente, uma equipe de cientistas da Japan Advanced Institute of Science and Technology (JAIST) desenvolveu um novo framework, denominado SPECTRA, que visa acelerar a geração de texto, essencial para aplicações como chatbots e assistentes de código.
Método proposto
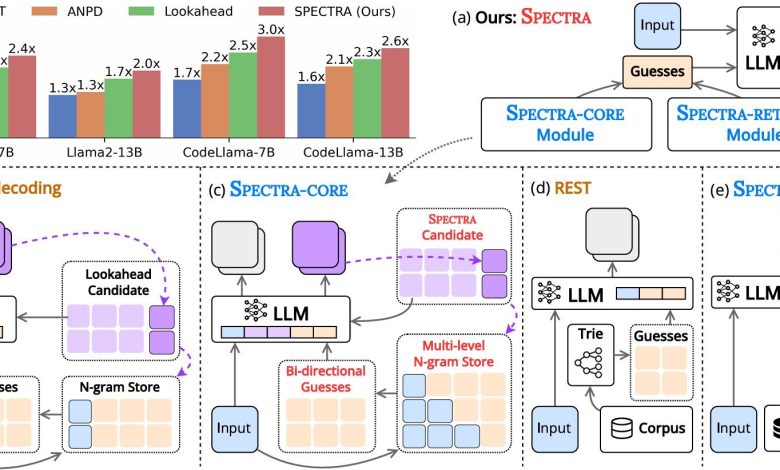
O SPECTRA utiliza um método de decodificação especulativa que permite que um modelo menor de LLM faça várias suposições sobre os tokens de texto simultaneamente, os quais são então verificados pelo modelo original. Isso reduz significativamente o tempo necessário para a geração de respostas. O framework é composto por dois módulos: o módulo central SPECTRA-CORE, que se integra facilmente aos LLMs, e um módulo de recuperação opcional SPECTRA-RETRIEVAL que melhora ainda mais o desempenho.
“O framework consiste em dois componentes principais: um módulo central (SPECTRA-CORE), que se integra perfeitamente aos LLMs de maneira plug-and-play, e um módulo de recuperação opcional (SPECTRA-RETRIEVAL) que melhora ainda mais o desempenho.”
(“The framework consists of two main components: a core module (SPECTRA-CORE), which integrates seamlessly into LLMs in a plug-and-play manner, and an optional retrieval module (SPECTRA-RETRIEVAL) that further enhances performance.”)— Nguyen Le Minh, Professor, JAIST
Resultados e impacto
A equipe de pesquisa testou o SPECTRA em seis tarefas, incluindo conversas de múltiplas interações, geração de código e raciocínio matemático, utilizando três famílias de LLM: Llama 2, Llama 3 e CodeLlama. Os resultados mostraram um aumento de desempenho de até 4x, superando métodos avançados de decodificação não treinada, como REST, ANPD e Lookahead. O SPECTRA demonstrou ser confiável em diversos modelos e conjuntos de dados, otimizando as taxas de aceleração.
“Ao integrar nosso módulo SPECTRA-CORE, que utiliza armazenamento N-gram em múltiplos níveis e busca bidirecional, com o módulo SPECTRA-RETRIEVAL, que seleciona pistas externas de alta qualidade por meio de filtragem baseada em perplexidade, conseguimos obter acelerações substanciais (até 4,08x) em diversas tarefas e arquiteturas de modelos, preservando a qualidade do output original.”
(“By integrating our plug-and-play SPECTRA-CORE module—which leverages multi-level N-gram storage and bidirectional search—with the refined SPECTRA-RETRIEVAL module that selects high-quality external cues via perplexity-based filtering, we were able to achieve substantial speedups (up to 4.08×) across diverse tasks and model architectures while preserving the original model’s output quality.”)— Nguyen Le Minh, Professor, JAIST
O SPECTRA oferece uma solução prática para sistemas comerciais e de pesquisa que utilizam LLMs, potencialmente melhorando a acessibilidade e a sustentabilidade de IAs de alto desempenho a longo prazo. Futuras pesquisas podem explorar integrações adicionais e otimizações para expandir ainda mais o escopo de aplicações deste framework.
Fonte: (TechXplore – Machine Learning & AI)