Uma nova abordagem em machine learning promete avaliações mais justas para modelos de AI
São Paulo — InkDesign News — Pesquisadores da Universidade de Stanford desenvolveram um método inovador que promete tornar as avaliações de modelos de linguagem de inteligência artificial (AI) mais rápidas, justas e econômicas.
Contexto da pesquisa
A avaliação de modelos de AI frequentemente se baseia em bancos de questões abrangentes, que requerem análise humana para validar as respostas. Contudo, essa metodologia pode ser cara e suscetível a viés, resultando em superestimações das melhorias entre diferentes versões dos modelos.
Método proposto
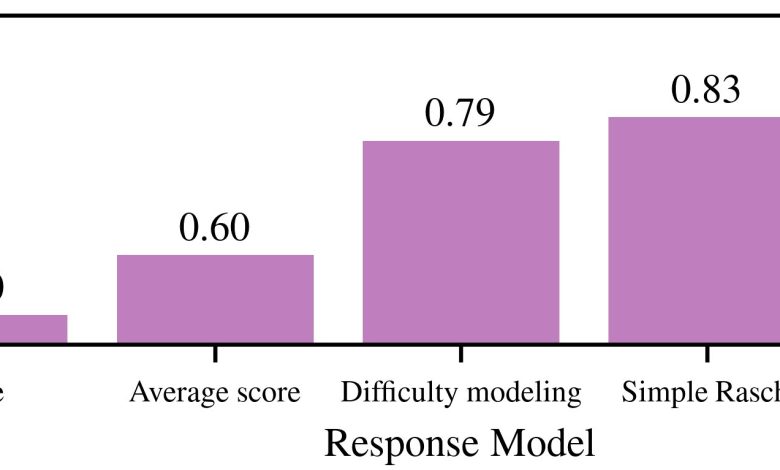
Os pesquisadores adotaram uma técnica chamada Teoria da Resposta ao Item (Item Response Theory), já utilizada na educação para avaliar a dificuldade das questões em testes padronizados. “A chave da nossa observação é considerar a dificuldade das perguntas”, afirmou Sanmi Koyejo, professor assistente da Universidade de Stanford. (“The key observation we make is that you must also account for how hard the questions are.”)
“As avaliações podem, muitas vezes, custar tanto quanto ou mais do que o treinamento do próprio modelo.”
(“This evaluation process can often cost as much or more than the training itself.”)— Sang Truong, Candidato a doutorado, Laboratório de Inteligência Artificial de Stanford (SAIL)
Aplicando esta abordagem, eles foram capazes de reduzir os custos das avaliações em até 80%, utilizando modelos de linguagem para classificar as questões por dificuldade.
Resultados e impacto
Os resultados foram encorajadores, demonstrando que a nova metodologia não apenas economiza recursos, mas também permite uma comparação mais justa entre diferentes modelos. Koyejo testou o sistema contra 22 conjuntos de dados e 172 modelos de linguagem, observando que ele se adaptou facilmente a novas questões e modelos.
“Essa abordagem permite avaliações mais robustas, promovendo diagnósticos mais precisos e comparações de desempenho mais adequadas entre modelos.”
(“This approach puts rigorous, scalable, and adaptive evaluation within reach.”)— Sanmi Koyejo, Professor Assistente, Universidade de Stanford
No geral, essa inovação pode mudar a forma como as avaliações de modelos de linguagem são conduzidas, promovendo um ambiente de pesquisa mais transparente e confiável. A escalabilidade da abordagem sugere que ela pode ser aplicada a vários domínios do conhecimento, desde medicina até direito.
O próximo passo para os pesquisadores envolve expandir o uso desta nova metodologia para cobrir um espectro ainda mais amplo de testes e ambientes, o que pode acelerar o desenvolvimento de ferramentas de inteligência artificial confiáveis e seguras.
Fonte: (TechXplore – Machine Learning & AI)