São Paulo — InkDesign News — O modelo CLIP, desenvolvido pela OpenAI, tem se destacado no campo de machine learning, sendo utilizado em projetos de visão computacional e processamento de linguagem natural. Sua arquitetura e capacidade de zero-shot learning garantem resultados promissores.
Arquitetura de modelo
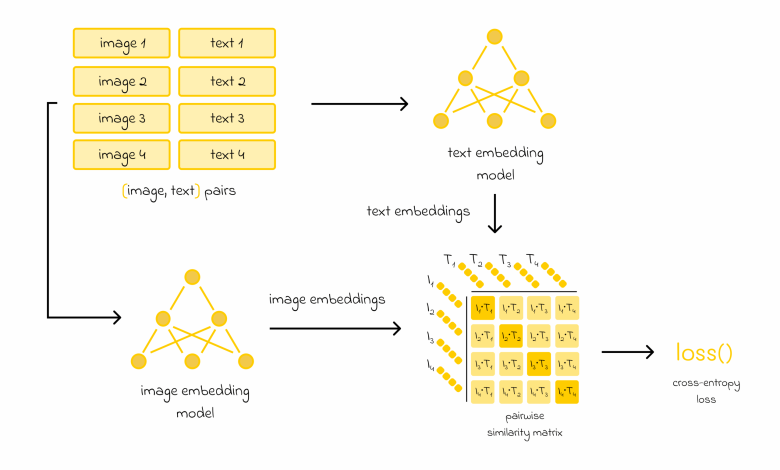
O CLIP combina modelos de embedding de texto e imagem. Utilizando uma arquitetura baseada em Transformers para textos, similar ao BERT, e redes convolucionais ou um Vision Transformer para imagens, o modelo busca aprender representações significativas a partir de um abrangente conjunto de dados de 400 milhões de pares de imagens e textos.
“O objetivo consistiu em construir representações de embedding significativas, cuja similaridade medisse quão semelhante é uma descrição de texto em relação a uma imagem.”
(“The goal consisted of constructing meaningful embedding representations such that the similarity between them would measure how similar a given text description is with respect to an image.”)— Autor não especificado
Treinamento e otimização
Durante o treinamento, cada imagem e texto do lote gera pares de embeddings, e uma matriz de similaridade é criada. O modelo busca maximizar a similaridade entre pares corretos e minimizar entre aqueles que não correspondem. A função de perda utilizada é a cross-entropy, o que garante uma atualização eficiente dos pesos dos modelos.
Resultados e métricas
O CLIP demonstra um desempenho comparável a modelos supervisionados em várias tarefas de classificação e em zero-shot learning. A eficiência computacional é uma vantagem significativa, permitindo que muitos cálculos sejam feitos em paralelo. No entanto, enquanto o CLIP se sai bem em tarefas padrão de visão computacional, as limitações em tarefas mais específicas, como reconhecimento de caracteres, são notórias.
“Apesar de que o CLIP possui capacidades impressionantes de zero-shot, ainda existem tipos de imagens muito específicos em que o modelo não foi treinado.”
(“Despite the fact that CLIP has impressive zero-shot capabilities, there can still exist very specific image types on which CLIP has not been trained.”)— Autor não especificado
As aplicações do CLIP são extensivas, incluindo desde tarefas de classificação de imagens até sistemas de recomendação baseados em similaridade. Para o futuro, a pesquisa pode se concentrar em aprimorar suas capacidades em áreas específicas, além de otimizar ainda mais sua eficiência em tarefas de alto volume computacional.
Fonte: (Towards Data Science – AI, ML & Deep Learning)































