São Paulo — InkDesign News — O conceito de multi-armed bandits é fundamental para entender como machine learning opera em ambientes com incerteza, permitindo decisões eficientes entre exploração e exploração para maximizar recompensas.
Arquitetura de modelo
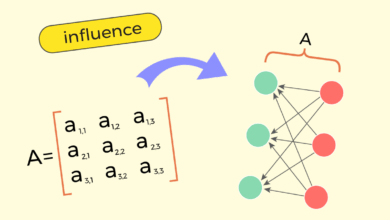
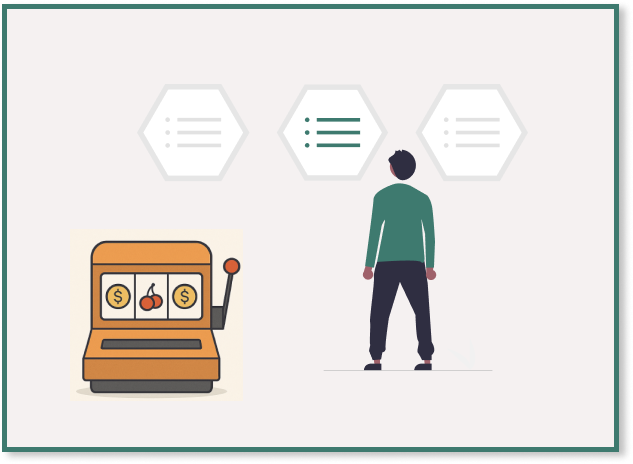
O modelo de multi-armed bandits é usado para ilustrar o dilema entre explorar opções novas ou explorar as já conhecidas. Em essência, a abordagem envolve um agente que precisa decidir qual “braço” (ou opção) puxar em uma máquina de caça-níqueis, onde cada braço possui uma probabilidade desconhecida de retorno. A diferença crucial entre humano e máquina é que esta última consegue otimizar essa decisão matematicamente.
“A aprendizagem através de tentativas e erros dos máquinas não é muito diferente do que fazemos intuitivamente.”
(“What machines learn by trial and error is not so different from what we humans do intuitively.”)— Autor, Estudioso de AI
Treinamento e otimização
A implementação do algoritmo pode incluir diversas estratégias. A estratégia ε-Greedy, por exemplo, permite ao agente explorar com uma certa probabilidade, promovendo um equilíbrio entre exploração e exploração. Esse método é frequentemente considerado prático e eficaz, facilitando a descoberta de novas opções enquanto ainda se retira valor das decisões anteriores.
“O problema está em que nunca sabemos com certeza se já encontramos a melhor opção.”
(“The problem with this? We never know for sure whether we have already found the best option.”)— Autor, Estudioso de AI
Resultados e métricas
A análise de desempenho do modelo pode ser medida pela precisão da expectativa de recompensa Q(a), que deve se aproximar da verdadeira distribuição de recompensa a longo prazo. O desempenho do modelo em ambientes não estacionários, por exemplo, pode rotear as avaliações de recompensa usando a método incremental para se ajustar rapidamente a novas informações.
“Se um ambiente é estável e as recompensas não mudam, o método de média amostral funciona melhor.”
(“If the environment is stable and rewards don’t change, the sample average method works best.”)— Autor, Estudioso de AI
A aplicação prática do modelo multifacetado de multi-armed bandits tem implicações em vários campos, incluindo recomendações personalizadas, anúncios online e otimização de estratégias de marketing. Pesquisas futuras focarão em melhorar a interação entre exploração e exploração para renderizar sistemas ainda mais eficientes.
Fonte: (Towards Data Science – AI, ML & Deep Learning)