Anthropic apresenta diretrizes para LLM com inteligência artificial

São Paulo — InkDesign News — A inteligência artificial (IA) e os modelos de linguagem de grande porte (LLM) estão cada vez mais integrados em diversas aplicações comerciais, exigindo que as empresas desenvolvam estruturas robustas para garantir segurança e interpretabilidade.
Tecnologia e abordagem
A Anthropic, um laboratório de IA fundado por ex-funcionários do OpenAI, tem focado no conceito de “Constitucional AI”, que enfatiza a criação de modelos que sejam “úteis, honestos e inofensivos”. O modelo principal da empresa, Claude 4.0 Opus, é um exemplo da aplicação de princípios éticos e pode ser considerado um avanço nas abordagens de IA baseada em princípios humanos.
Aplicação e desempenho
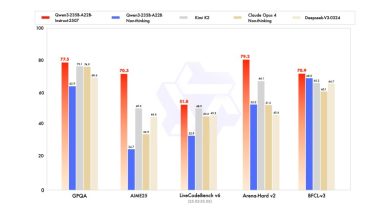
Claude tem demonstrado desempenho superior em benchmarks de codificação. O modelo alcançou resultados significativos, mas enfrenta competição de rivais como Google’s Gemini 2.5 Pro e OpenAI. Além disso, a Anthropic investe na pesquisa de interpretabilidade, essencial em ambientes onde decisões afetam diretamente indivíduos, como na medicina e na avaliação de crédito.
Precisamos entender como a IA pensa para prever comportamentos prejudiciais e garantir decisões safe
(“Our inability to understand models’ internal mechanisms means that we cannot meaningfully predict such [harmful] behaviors”)— Dario Amodei, CEO, Anthropic
Um dos desafios permanece na “opacidade” dos modelos de IA, que pode prejudicar a confiabilidade em configurações críticas. A capacidade de explicar decisões de IA é vital para a aceitação em setores regulados e para a redução de custos operacionais a longo prazo.
Impacto e mercado
Empresas como Amazon e Google já investiram bilhões na Anthropic, reconhecendo o potencial do laboratório em facilitar a construção de modelos mais interpretáveis, o que pode representar uma vantagem competitiva significativa no mercado em rápida evolução da IA. A necessidade de modelos interpretáveis é cada vez mais evidente, já que isso pode reduzir riscos e custos associados ao uso de IA em sistemas complexos.
Embora a interpretabilidade seja valiosa, é apenas uma ferramenta entre muitas para gerenciar o risco de IA
(“interpretability is neither necessary nor sufficient”)— Sayash Kapoor, Pesquisador de segurança em IA, Princeton
Os próximos passos para a Anthropic incluem a ampliação de suas pesquisas em interpretabilidade, colaborando com outras instituições e investindo em ferramentas para análise profunda dos modelos. Essa abordagem é essencial para garantir que modelos de IA possam ser usados de forma confiável e responsável, especialmente em decisões que afetam diretamente a sociedade.
Fonte: (VentureBeat – AI)