São Paulo — InkDesign News —
Pesquisadores estão utilizando técnicas de machine learning para avançar na criação de modelos de linguagem-visual, com o objetivo de melhorar a capacidade de sistemas de inteligência artificial (AI) na interpretação de ambientes e interação com usuários.
Contexto da pesquisa
Uma equipe de pesquisadores do Instituto Italiano de Tecnologia (IIT) e da Universidade de Aberdeen apresentou um novo framework conceitual e um dataset que pode ser utilizado para treinar modelos de linguagem-visual (VLMs) em tarefas de raciocínio espacial. O trabalho, publicado em um paper no arXiv, busca contribuir para o desenvolvimento de sistemas de AI que consigam navegar de maneira mais eficaz em ambientes reais.
Método proposto
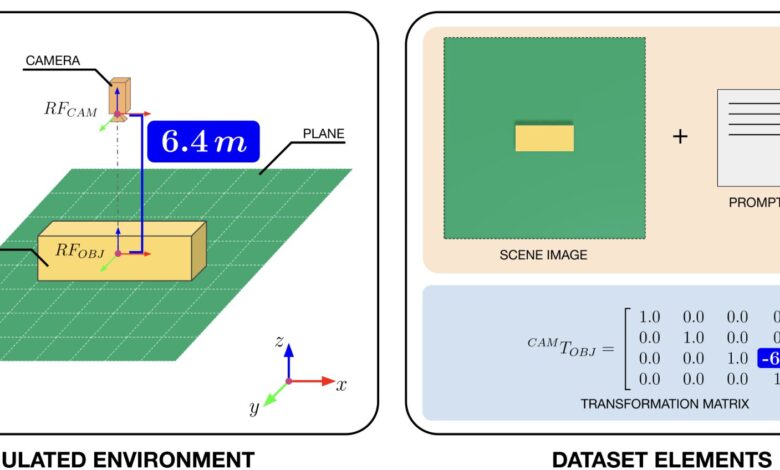
A pesquisa é parte do projeto FAIR e resulta de uma colaboração entre a linha de pesquisa Social Cognition in Human-Robot Interaction (S4HRI) do IIT e o Action Prediction Lab da Universidade de Aberdeen. Os pesquisadores desenvolveram um dataset contendo dados gerados computacionalmente, com o auxílio da plataforma Omniverse Replicator da NVIDIA, que captura imagens em 3D de um cubo a partir de diferentes ângulos e distâncias.
“Nosso principal objetivo era permitir que os robôs raciocinassem de maneira efetiva sobre o que outros agentes podem ou não perceber a partir de seus pontos de vista em ambientes compartilhados”
(“Our primary objective was to enable robots to reason effectively about what other agents (human or artificial) can or cannot perceive from their vantage points within shared environments.”)— Davide De Tommaso, Tecnólogo, IIT
O dataset consiste em pares de imagens e matrizes de transformação, que representam a posição e a orientação do cubo. Essa abordagem oferece uma nova maneira de os modelos aprenderem sobre a percepção visual alheia, permitindo que robôs compreendam não apenas o que veem, mas também como isso é percebido por outros.
Resultados e impacto
Os resultados preliminares indicam que o uso de representações sintéticas de cena, combinadas com modelos de linguagem de grande escala, apresenta um potencial significativo para o desenvolvimento de capacidades de percepção visual em robôs. Joel Currie, primeiro autor do estudo, enfatiza a importância do dataset: “É uma forma de ensinar os robôs a não apenas ver, mas a entender o espaço como um ser físico faria”
(“It’s a way of teaching robots to not just see, but to understand space like a physical being would.”).
Embora o framework ainda seja teórico, ele poderá ser utilizado em treinos futuros de modelos reais. O próximo passo é tornar o ambiente virtual o mais realista possível, para que o conhecimento adquirido em simulação possa ser transferido para o mundo real.
As aplicações potenciais incluem melhorias na interação entre humanos e robôs, especialmente em cenários onde ambos compartilham uma compreensão espacial do ambiente. Isso pode revolucionar o campo da robótica e da inteligência artificial.
Fonte: (TechXplore – Machine Learning & AI)