Um novo modelo de machine learning desenvolvido por pesquisadores do MIT promete melhorar a capacidade da inteligência artificial (IA) em entender a conexão entre áudio e vídeo, aproximando-a da forma como os humanos aprendem.
Contexto da pesquisa
A pesquisa, liderada por Edson Araujo, aluno de pós-graduação na Universidade Goethe, visa aprimorar a aprendizagem de máquinas em cenários multimodais, onde áudio e dados visuais estão interligados. De acordo com Araujo, “estamos construindo sistemas de IA que conseguem processar o mundo como os humanos fazem, em termos de ter informações auditivas e visuais recebendo dados simultaneamente” (“We are building AI systems that can process the world like humans do, in terms of having both audio and visual information coming in at once”).
“Estamos construindo sistemas de IA que conseguem processar o mundo como os humanos fazem.”
(“We are building AI systems that can process the world like humans do.”)— Edson Araujo, Aluno de Pós-Graduação, Universidade Goethe
Método proposto
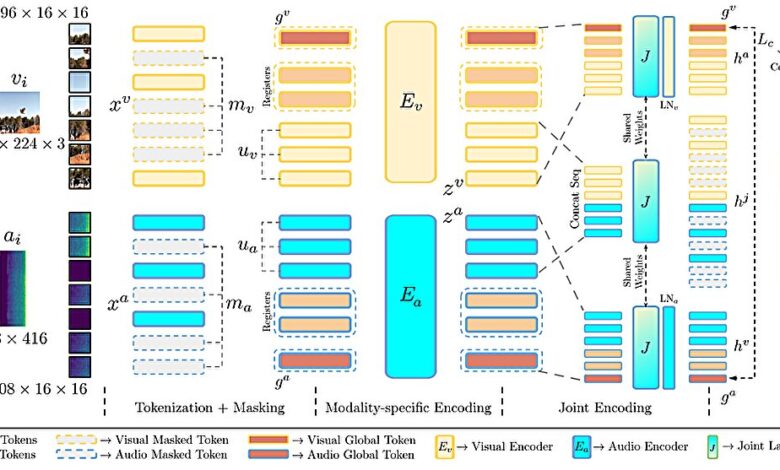
O modelo, denominado CAV-MAE Sync, é uma evolução de um método anterior desenvolvido pelo mesmo grupo. Este modelo utiliza codificadores separados para processar quadros de vídeo e segmentos de áudio simultaneamente, permitindo uma correspondência mais precisa entre ambos. O modelo aprende a associar um quadro de vídeo específico ao áudio correspondente, oferecendo maior granularidade na relação entre os dados auditivos e visuais.
Durante o treinamento, cada janela de áudio é mapeada independentemente, permitindo que a IA reconheça, por exemplo, o som de uma porta batendo enquanto a porta se fecha visualmente. Além disso, a introdução de “tokens globais” e “tokens de registro” ajuda a aprimorar a capacidade de aprendizado do modelo.
Resultados e impacto
Os resultados mostraram uma precisão superior em tarefas de recuperação de vídeo e classificação de ações em cenas audiovisuais. A performance do CAV-MAE Sync foi superior à de métodos mais complexos e que exigem conjuntos de dados maiores. Os pesquisadores observaram que, em certas situações, “ideias simples ou padrões que você vê nos dados têm um grande valor quando aplicados a um modelo” (“Sometimes, very simple ideas or little patterns you see in the data have big value when applied on top of a model”).
“Ideias simples têm um grande valor quando aplicadas a um modelo.”
(“Sometimes, very simple ideas or little patterns you see in the data have big value when applied on top of a model.”)— Edson Araujo, Aluno de Pós-Graduação, Universidade Goethe
As aplicações potenciais deste método incluem melhorias em ambientes robóticos e curadoria automática de conteúdo multimodal em áreas como jornalismo e produção de filmes. Os pesquisadores também almejam integrar novas representações de dados e expandir a funcionalidade do modelo para lidar com dados textuais, levando a um avanço em modelos de linguagem audiovisual.
Fonte: (TechXplore – Machine Learning & AI)