São Paulo — InkDesign News — Um estudo recente traz inovações na área de machine learning, explorando técnicas de destilação de conhecimento, onde modelos de maior complexidade são utilizados para treinar modelos mais leves, sem perder desempenho significativo.
Arquitetura de modelo
O experimento feito por um pesquisador envolveu um modelo “teacher” baseado no RoBERTa-large, finetuning aplicado a um classificador de intenções. O responsável buscava estratégias eficientes de alinhamento entre as camadas do modelo teacher e um modelo aluno, visando maximizar a eficácia do aprendizado.
Treinamento e otimização
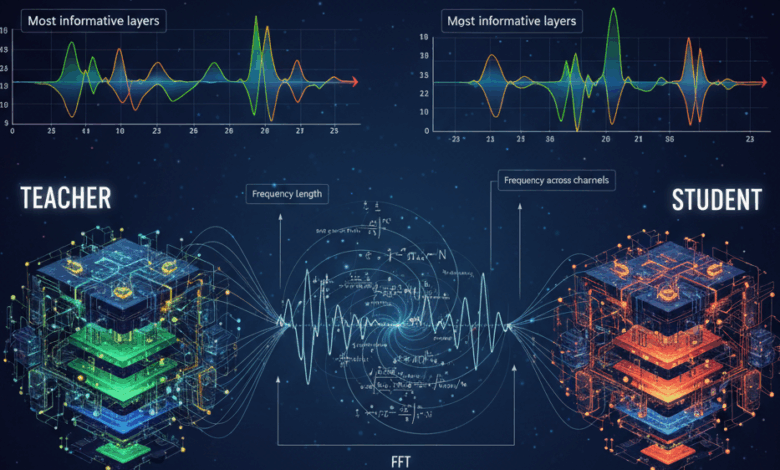
Diversas estratégias de conexão entre camadas foram testadas, incluindo a interligação de toda segunda camada e a média de duas camadas, mas o desempenho do modelo aluno permaneceu aquém do esperado. Como solução, o pesquisador recorreu ao paper “SpectralKD: A Unified Framework for Interpreting and Distilling Vision Transformers via Spectral Analysis”, que aplica análise espectral para entender a passagem de informações em modelos de aprendizado. A abordagem foi adaptada ao domínio de processamento de linguagem, resultando em uma seleção eficaz de camadas para a destilação de conhecimento.
“A análise espectral ofereceu uma nova perspectiva sobre como as informações fluem nas camadas do modelo”, explica o autor do estudo.
Resultados e métricas
A implementação da análise espectral resultou na escolha das camadas 1 a 9 e 21 a 23 do modelo RoBERTa-large para o aluno, levando a um aumento significativo na precisão do modelo. Isso demonstra que não todas as camadas são igualmente importantes; as primeiras e as camadas finais desempenham um papel crucial na transferência de informação.
Com a aplicação do `Fast Fourier Transform` (FFT), foi possível identificar a intensidade espectral de cada camada, ajudando a quantificar quais partes da arquitetura realmente contribuíam para o aprendizado. Essa estratégia não apenas elevou a performance do modelo aluno, como também revelou padrões comuns entre diferentes arquiteturas de transformadores.
“Uma nova abordagem para alinhamento espectral não só melhora o aprendizado, mas também proporciona uma compreensão mais profunda do funcionamento interno dos modelos”, finaliza o autor.
Esse estudo abre portas para melhorias em aplicações práticas e avança o conhecimento sobre a dinâmica de destilação em modelos de aprendizado profundo.
Fonte: (Towards Data Science – AI, ML & Deep Learning)