São Paulo — InkDesign News —
Pesquisadores de inteligência artificial (AI) e machine learning desenvolveram um modelo baseado em difusão que utiliza reforço para aprimorar o raciocínio em grandes modelos de linguagem (LLMs). A abordagem, criada pela Universidade da Califórnia, Los Angeles, combina técnicas inovadoras para aumentar a eficiência computacional e a precisão em tarefas complexas.
Contexto da pesquisa
Nos últimos anos, o uso de LLMs cresceu exponencialmente, exigindo grande consumo de energia em data centers. Alternativas como modelos baseados em difusão (dLLMs) vêm sendo exploradas para reduzir essa demanda. Diferentemente dos LLMs autorregressivos tradicionais, os dLLMs operam por um processo de difusão reversa, originalmente aplicado em geração de imagens, adaptado para texto via mascaramento de tokens, o que pode exigir menor poder computacional. Entretanto, a capacidade de raciocínio desses modelos ainda é inferior.
Método proposto
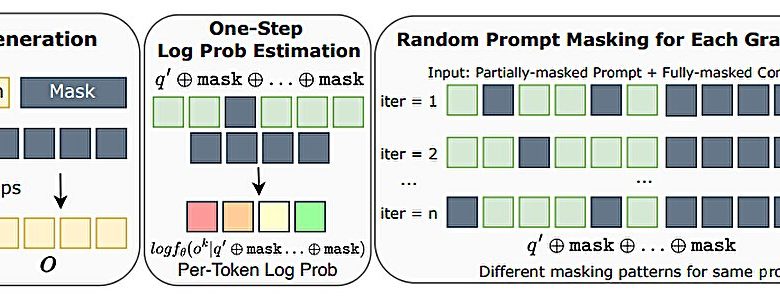
A equipe da UCLA instituiu um processo em duas etapas para o desenvolvimento do d1, um framework que combina dLLMs com aprendizado por reforço. Primeiramente, adotaram fine-tuning supervisionado com dados de alta qualidade. A segunda etapa aplica o algoritmo diffu-GRPO, que utiliza princípios matemáticos para inferência de alta ordem junto a uma técnica chamada “mascaramento aleatório de prompts” (“random prompt masking”). Essa combinação visa melhorar o raciocínio lógico e matemático do modelo.
“Para ampliar o raciocínio em modelos de linguagem grandes baseados em difusão, utilizamos aprendizado por reforço em combinação com ajuste fino supervisionado.”
(“To scale reasoning in diffusion large language models, we used reinforcement learning in combination with supervised fine-tuning.”)— Siyan Zhao, Pesquisador, UCLA
Resultados e impacto
Testes do d1 mostraram desempenho superior em benchmarks de matemática e raciocínio lógico, demonstrando que a abordagem pode superar modelos baseados em LLaDA-8BInstruct. A efetividade do diffu-GRPO no contexto dLLM representa um avanço científico que reduz a necessidade de recursos computacionais e melhora a aplicabilidade dos modelos. Ainda, o framework está aberto para ser testado e adaptado por outros pesquisadores.
“Modelos utilizando diffu-GRPO consistentemente superam o modelo base em quatro tarefas de raciocínio lógico e matemático.”
(“Models using diffu-GRPO consistently outperform the base model on four logical and math reasoning tasks.”)— Siyan Zhao, Pesquisador, UCLA
Os próximos passos indicam testes ampliados em diferentes domínios, além da integração em aplicações práticas de NLP com restrições computacionais. A proposta traz potencial para expansão em modelos de linguagem eficientes e sustentáveis.
Fonte: (TechXplore – Machine Learning & AI)