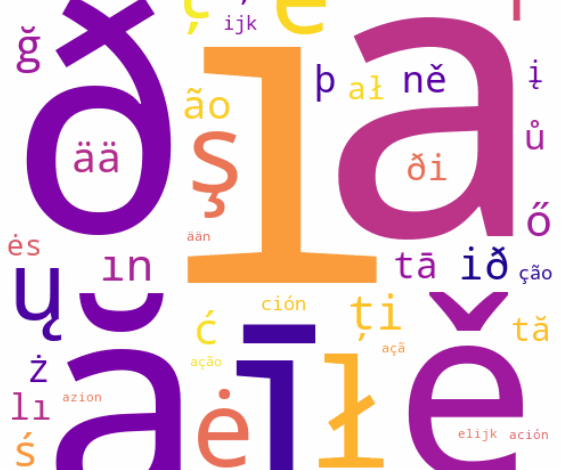
São Paulo — InkDesign News — Um novo estudo emprega técnicas de machine learning para desvendar padrões característicos de 20 línguas europeias, utilizando estatísticas para detectar características distintivas do texto.
Arquitetura de modelo
O estudo destaca como medir o quão distinto um padrão de caracteres é em comparação a outras línguas. A metodologia se concentra na análise de sequências de caracteres para identificar suas “impressões digitais” linguísticas. Para quantificar a singularidade, foram utilizados conjuntos L (todas as línguas estudadas) e S (todos os padrões de caracteres observados).
“Quão mais provável é esse padrão aparecer em uma linguagem em comparação a todas as outras?”
(“How much more likely is this pattern to appear in one language compared to all others?”)— Pesquisador, Instituição
Treinamento e otimização
O modelo implementa uma métrica chamada razão de verossimilhança (LR), que compara a probabilidade de um padrão de caracteres aparecer em uma língua específica em vez de qualquer outra. Durante a análise, a suavização aditiva foi aplicada para lidar com contagens zero, evitando a divisão por zero e permitindo uma análise mais equilibrada.
“Essa técnica garante que um padrão raro não domine apenas por ser exclusivo.”
(“This technique ensures that a rare pattern doesn’t automatically dominate just because it’s exclusive.”)— Pesquisador, Instituição
Resultados e métricas
A análise utilizou o pacote Python wordfreq para coletar 5.000 das palavras mais frequentes em cada uma das 20 línguas. O resultado foi um conjunto abrangente de mais de 180.000 padrões únicos, possibilitando a extração de padrões estatísticos significativos. Os cinco padrões de caracteres mais distintos para cada língua, medidos por logaritmos da razão de verossimilhança, demonstraram que caracteres únicos, como “ð” em islandês e “ç” em português, aparecem com alta frequência.
“Isso oferece uma maneira divertida e fundamentada estatisticamente para explorar o que torna as línguas visualmente distintas.”
(“This offers a fun and statistically grounded way to explore what sets languages apart visually.”)— Pesquisador, Instituição
A pesquisa mostra o potencial de aplicação dessas análises em áreas como processamento de linguagem natural (NLP) e identificação de textos, assim como as implicações para futuras investigações sobre linguagem e aprendizado de máquina.
Fonte: (Towards Data Science – AI, ML & Deep Learning)