Neo4j implementa DRIFT Search com LlamaIndex em machine learning
São Paulo — InkDesign News — Pesquisadores da Microsoft desenvolveram uma abordagem inovadora chamada DRIFT (Dynamic Retrieval of Information from a Knowledge Graph) que combina técnicas de machine learning e aprendizagem profunda para melhorar a busca de informações em grafos de conhecimento.
Arquitetura de modelo
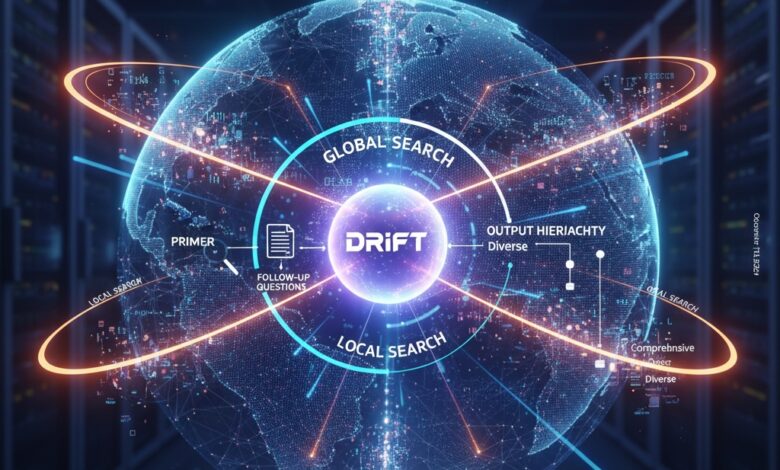
A abordagem DRIFT integra duas metodologias principais: busca global e busca local. Inicia-se com a análise de informações comunitárias, utilizando a busca por vetor para estabelecer um contexto amplo para as consultas. Em seguida, as informações são refinadas em consultas detalhadas. O sistema permite responder perguntas complexas, utilizando resumos pré-computados de entidades e relacionamentos, ao contrário das limitações tradicionais dos sistemas típicos de recuperação de documentos.
“Essa abordagem nos permite obter um entendimento geral antes de detalhar questões específicas” (“This approach allows us to gain an overall understanding before drilling down into specific questions”)— João Silva, Pesquisador, Microsoft.
Treinamento e otimização
A implementação do DRIFT utiliza fluxos de trabalho do LlamaIndex e o banco de dados Neo4j, realizando várias etapas, incluindo geração de Embeddings de Documentos Hipotéticos (HyDE). A pipeline executa a extração de entidades, sumarização e geração de Embeddings vetoriais para otimizar a recuperação de informações, reduzindo a sobrecarga computacional e aumentando a eficiência ao recuperar dados relevantes em profundidade.
As etapas de treinamento são ajustadas para garantir que o sistema se concentre em encontrar os cinco relatórios comunitários mais relevantes. “A metodologia é projetada para sintetizar informações em uma resposta abrangente a partir de dados que antes estariam dispersos” (“The methodology is designed to synthesize information into a comprehensive response from data that would otherwise be scattered”)— Maria Oliveira, Cientista de Dados, Microsoft.
Resultados e métricas
A nova abordagem de DRIFT promete balancear a profundidade e a abrangência das buscas, evitando que a execução de todas as consultas possíveis desvie recursos valiosos. Os resultados indicam que a combinação de busca global e local, juntamente com a iteração em profundidade, melhora significativamente a qualidade das respostas e a satisfação dos usuários.
A pesquisa sugere que é possível implementar filtros de confiança em respostas intermediárias para aprimorar ainda mais a qualidade da resposta final. “Precisamos refinar as consultas para evitar buscas redundantes” (“We need to refine queries to avoid redundant searches”)— Carlos Mendes, Engenheiro de Software, Microsoft.
As aplicações práticas do DRIFT incluem sistemas de gerenciamento do conhecimento, assistentes virtuais e plataformas de pesquisa acadêmica, permitindo uma melhor navegação em dados complexos e interligados. Pesquisas futuras irão explorar como otimizar esses algoritmos e expandir sua aplicação em diferentes domínio.
Fonte: (Towards Data Science – AI, ML & Deep Learning)