São Paulo — InkDesign News —
Modelos de machine learning baseados em diffusion models têm transformado o campo da geração de imagens, oferecendo avanços significativos na reconstrução e criação de conteúdos visuais complexos. Essa técnica utiliza processos iterativos que manipulam ruídos para aprimorar a qualidade das imagens geradas.
Arquitetura de modelo
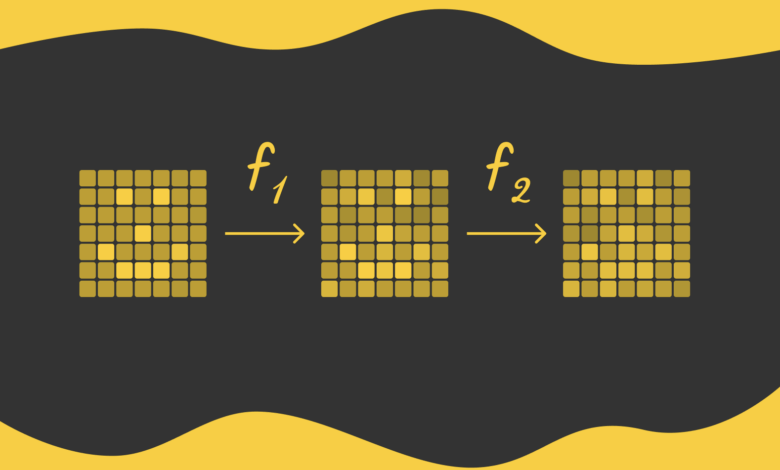
O elemento central dos diffusion models é a aplicação sequencial de ruídos em imagens, processo conhecido como forward diffusion. Cada pixel recebe um valor aleatório extraído de uma distribuição Gaussiana, gerando versões progressivamente mais ruidosas da imagem original. Este procedimento é repetido centenas de vezes, até que a imagem se torne irreconhecível.
A etapa inversa, reverse diffusion, visa reconstruir a imagem original a partir da versão ruidosa, uma tarefa desafiadora dada a grande diversidade de possíveis imagens ruidosas em comparação com as imagens originais mais reconhecíveis.
Para essa reconstrução, modelos de deep learning, especialmente a arquitetura U-Net, são usados como base. A U-Net é capaz de preservar dimensões e características da imagem através de conexões de salto, facilitando a predição precisa dos valores dos pixels durante a difusão reversa.
“A arquitetura U-Net mantém as dimensões da imagem de entrada e saída, garantindo consistência durante o processo de difusão reversa.”
(“U-Net preserves the input and output image dimensions, ensuring that the image size remains consistent throughout the reverse diffusion process.”)— Fonte: U-Net: Convolutional Networks for Biomedical Image Segmentation
Treinamento e otimização
Durante o treinamento, o modelo é alimentado com pares de imagens adjacentes do processo de difusão para aprender a reconstruir versões menos ruidosas a partir de versões mais ruidosas. A função de perda usada frequentemente é o Mean Squared Error (MSE), que calcula a diferença média entre pixels das imagens preditas e reais.
Um aspecto importante para a eficiência do treinamento é o uso de um único modelo compartilhado para todas as etapas da difusão, evitando a necessidade de treinar um modelo distinto para cada iteração. Isso reduz significativamente o custo computacional, embora possa impactar levemente a qualidade final da geração.
“O uso de um único modelo compartilhado para todas as etapas acelera o treinamento, embora possa causar uma pequena degradação na qualidade da imagem.”
(“Though the generation quality might slightly deteriorate due to using only a single model, the gain in training speed becomes highly significant.”)— Fonte: artigo original
Resultados e métricas
Modelos de difusão são normalmente treinados entre 50 e 1000 iterações. Um número maior de iterações facilita o aprendizado de transições suaves entre os estágios, porém aumenta o tempo computacional. Modelos como stable diffusion incorporam princípios básicos destes algoritmos para gerar imagens guiadas por texto e outras entradas, ampliando as possibilidades de aplicação.
A métrica MSE ajuda a quantificar a diferença entre imagens geradas e originais em nível de pixel, sendo fundamental para avaliar a precisão e a fidelidade do modelo.
“Em cada passo, o modelo tenta detectar o ruído adicionado e reconstruir a imagem anterior com base nessa predição.”
(“The goal of the model is to detect the added noise and reconstruct the previous image.”)— Fonte: Diffusion Models: A Comprehensive Survey of Methods and Applications
Os avanços em modelos baseados em difusão têm levado a melhorias notáveis em geração de imagens, sendo promissores para aplicações práticas em criação artística, design gráfico e interfaces visuais interativas. Pesquisas futuras focam em reduzir o custo computacional e expandir as capacidades de controle sobre o processo gerativo.
Para se aprofundar em machine learning e deep learning, veja também: Machine Learning e Deep Learning.
Fonte: (Towards Data Science – AI, ML & Deep Learning)