Brown University — InkDesign News — Pesquisadores desenvolveram um modelo de machine learning capaz de gerar trajetórias de movimento em robôs e avatares animados a partir de comandos em linguagem natural.
Contexto da pesquisa
A pesquisa conduzida na Brown University propõe um avanço no uso de inteligência artificial (IA) para interpretar e executar comandos textuais traduzidos em movimentos físicos ou virtuais. Modelos de linguagem grande (LLMs), como o ChatGPT, já aplicam previsões tokenizadas para gerar texto, técnica que os autores aplicam agora à geração de movimentos. O desafio principal consiste em representar movimentos para diferentes “corpos”, que possuem dimensões e tipos de locomação distintos, como robôs quadrúpedes e humanos.
Método proposto
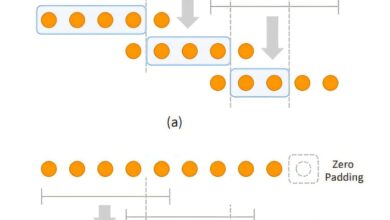
Chamado MotionGlot, o modelo usa a metodologia de tokenização de movimentos, onde movimentos são decompostos em elementos discretos para que o sistema possa prever a sequência seguinte do movimento, semelhante ao processo que gera texto em LLMs. MotionGlot traduz tipos de movimento entre diversas entidades, respeitando as diferentes dimensões e modalidades de ação.
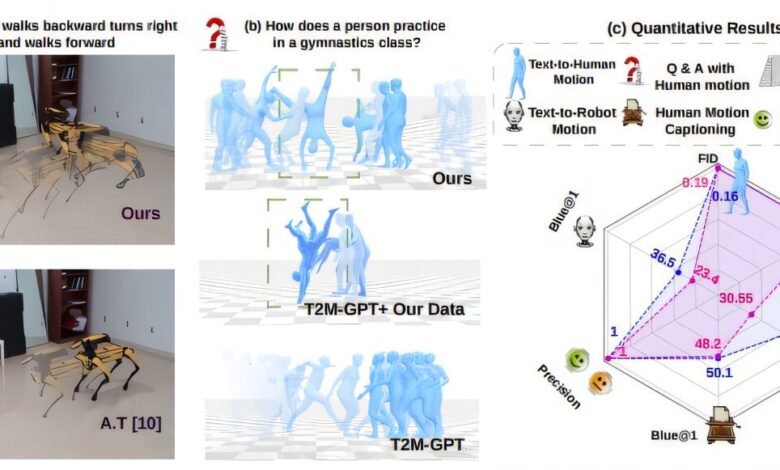
Para o treinamento, usaram-se os datasets QUAD-LOCO, com dados de robôs quadrúpedes, e QUES-CAP, com movimentos humanos anotados e legendados em detalhes. O modelo considera comandos textuais desde descrições específicas, como “andar para trás, virar à esquerda e andar para frente”, até conceitos abstratos como “andar felizmente”.
Resultados e impacto
O modelo demonstrou alta fidelidade na geração de movimentos precisos e contextualmente adequados, inclusive para ações nunca vistas durante o treinamento. Por exemplo, ao ser questionado sobre movimentos de atividade cardiovascular, gerou a imagem de uma pessoa correndo. Testes incluíram tarefas de tradução de comandos para diferentes robôs, assegurando desempenho consistente em múltiplos corpos e condições espaciais.
“Estamos tratando o movimento simplesmente como outra linguagem.”
(“We’re treating motion as simply another language.”)— Sudarshan Harithas, Ph.D. Student, Brown University
“Estes modelos funcionam melhor quando são treinados com grandes volumes de dados. Com coleta em larga escala, o modelo pode ser facilmente ampliado.”
(“These models work best when they’re trained on lots and lots of data. If we could collect large-scale data, the model can be easily scaled up.”)— Srinath Sridhar, Assistant Professor, Brown University
As avaliações quantitativas e qualitativas indicam que MotionGlot apresenta desempenho robusto em comparação com modelos adaptados anteriormente, sugerindo seu potencial aplicabilidade em diversos setores.
Entre as aplicações futuras destacam-se a colaboração humano-robô, jogos, realidade virtual, animação digital e produção de vídeo. Os pesquisadores planejam tornar o modelo e código-fonte públicos para estimular avanços nessa área.
Fonte: (TechXplore – Machine Learning & AI)