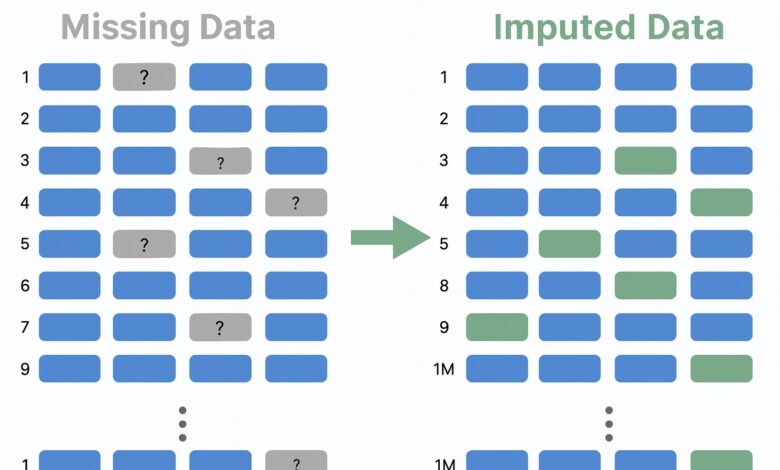
MissForest apresenta limitações em tarefas de machine learning
São Paulo — InkDesign News — Estudo recente discute os desafios no uso de técnicas de machine learning para imputação de dados ausentes, enfatizando a importância de evitar vazamentos de dados e garantir a integridade na avaliação de modelos.
Arquitetura de modelo
Muitos modelos de previsão enfrentam falhas quando são submetidos a dados incompletos. O estudo destaca três mecanismos de dados faltantes: MCAR (Missing Completely at Random), MAR (Missing at Random) e MNAR (Missing Not at Random). Esses mecanismos influenciam a escolha da técnica de imputação a ser utilizada.
A abordagem MissForest, que utiliza random forests para lidar com dados ausentes, é mencionada como uma solução que supera muitas das limitações das técnicas tradicionais, mas falha em armazenar modelos de imputação após o treinamento, comprometendo o uso no contexto de previsões.
A questão crucial é: “Como podemos imputar os dados de teste de maneira que permaneça totalmente consistente com as imputações aprendidas nos dados de treinamento?”
(“How can we impute the test data in a way that remains fully consistent with the imputations learned on the training data?”)— Autor, Instituição
Treinamento e otimização
A pesquisa revela que a falha em armazenar os parâmetros do modelo de imputação traz riscos significativos de vazamento de informações. Ao treinar o modelo de imputação nos dados de treinamento e aplicá-lo nos dados de teste, os resultados podem ser inflacionados, levando a estimativas otimistas de desempenho.
As soluções existentes incluem a combinação de dados de treinamento e teste antes da imputação, o que pode melhorar a qualidade da imputação, mas também pode resultar em comprometimento da avaliação. Essas preocupações são fundamentais para garantir que as métricas de desempenho sejam confiáveis e representativas.
Resultados e métricas
A aplicação prática da técnica MissForestPredict, uma versão adaptada do método original, promete resolver as limitações do MissForest no que tange às tarefas preditivas. Esta implementação é capaz de armazenar os modelos de imputação, permitindo sua reutilização em conjuntos de dados subsequentes, abordando assim a questão do uso de dados ausentes.
A utilização do algoritmo MissForestPredict para previsão é fundamental, pois garante que as imputações sejam consistentes em diferentes conjuntos de dados.
(“The use of the MissForestPredict algorithm for prediction is crucial as it ensures imputations are consistent across different datasets.”)— Autor, Instituição
Essa pesquisa abre caminho para avanços significativos em áreas onde a imputação de dados ausentes é crítica, como na saúde e em finanças, promovendo um uso mais eficaz de algoritmos preditivos.
Fonte: (Towards Data Science – AI, ML & Deep Learning)