Método simples permite publicação direta de achados em machine learning
Hanôver — InkDesign News — Pesquisadores do Leibniz Information Centre for Science and Technology (TIB), na Alemanha, propuseram uma abordagem que utiliza machine learning para viabilizar a produção e publicação direta de resultados científicos em formatos legíveis por máquinas, superando limitações das tradicionais publicações em PDF.
Contexto da pesquisa
Embora o uso de inteligência artificial (AI) tenha avançado em diversas áreas, a comunicação dos resultados científicos continua sendo feita majoritariamente em documentos textuais, que não são diretamente interpretáveis por máquinas. Isso impede reutilizações eficientes dos dados e torna trabalhosas as tarefas de extração automática por meio de técnicas convencionais de AI.
Direcionando-se ao problema da pouca acessibilidade dos resultados científicos para máquinas, pesquisadores do TIB questionaram por que não produzir ciência já em uma linguagem que os computadores compreendam nativamente.
Método proposto
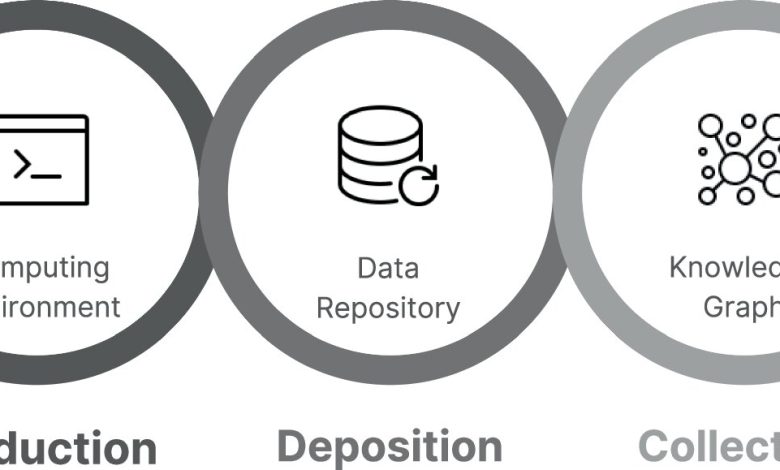
A equipe introduziu o conceito de “reborn articles” (artigos renascidos), uma abordagem open source que integra resultados de análises feitas em ambientes computacionais como R e Python diretamente em formatos de dados machine-readable, como arquivos CSV ou Excel, associados via metadados DOI aos artigos científicos.
O método transcende esforços tradicionais que treinam máquinas para extrair dados de PDFs por meio de modelos de AI, que apesar de seu uso popular, apresentam baixa precisão e demandam muito esforço manual.
“Muitos cientistas já usam ferramentas de análise de dados que produzem resultados que máquinas podem ler. Mas a forma padrão de publicar esses resultados é organizá-los em PDFs, que não são legíveis por máquinas. Isso significa que, se alguém quiser reutilizá-los, o que é o objetivo da publicação, precisa primeiro extrair e reestruturar os dados.”
(“Many scientists already use data analysis tools that produce results machines can read. But the standard way of publishing these results is to organize them in a PDF document that is not readable by machines. This means that if anyone wants to reuse these results, which is the entire point of publishing them, they first have to extract and restructure them.”)— Markus Stocker, Pesquisador, Leibniz Information Centre for Science and Technology
Resultados e impacto
A aplicação da metodologia promove resultados mais confiáveis e reprodutíveis, pois preserva a estrutura original dos dados sem perdas. O acesso direto a conjuntos de dados em formatos padronizados facilita pesquisas de síntese e metanálise, além de assegurar integridade e transparência dos achados científicos.
Este método evita a dependência exclusiva de modelos de AI para extração de informações, considerados inadequados para tarefas específicas. Os pesquisadores alertam para a necessidade de diversificar as abordagens em machine learning e AI, a fim de aumentar a eficiência na produção e disseminação do conhecimento científico.
“Imagine reformar sua casa tentando realizar todos os trabalhos apenas com uma furadeira. Isso não faz sentido. Preocupar-se apenas com a extração de informações pode nos fazer perder oportunidades de desenvolver ferramentas que executem certas tarefas com mais eficiência.”
(“Imagine renovating your home and trying to tackle every job with drilling tools. That just doesn’t make sense. I worry this fixation on information extraction will lead us to miss opportunities to develop tools that can tackle certain tasks more efficiently.”)— Lauren Snyder, Pesquisadora, Leibniz Information Centre for Science and Technology
O próximo passo dos pesquisadores é incentivar a adoção dessa abordagem disruptiva para que bases de conhecimento científico organizadas e legíveis por máquinas se tornem padrão, melhorando a reutilização de dados e acelerando novas descobertas.
Para mais informações, acesse /tag/machine-learning/ e /tag/deep-learning/.
Fonte: (TechXplore – Machine Learning & AI)