São Paulo — InkDesign News — Com o avanço do machine learning, técnicas como LoRA mostram como grandes modelos podem ser adaptados para tarefas específicas de forma eficiente e com menor consumo de recursos computacionais.
Arquitetura de modelo
Modelos modernos de linguagem, conhecidos como LLMs (Large Language Models), são frequentemente compostos por mais de um bilhão de parâmetros. Esses modelos exigem alto poder computacional, especialmente durante o processo de fine-tuning, onde seus pesos são adaptados para novos conjuntos de dados. Este processo pode ser demorado e intensivo em recursos, especialmente em máquinas locais com hardware limitado.
“Durante o fine-tuning, algumas camadas de redes neurais podem ser congeladas para reduzir a complexidade do treinamento, mas essa abordagem ainda é insuficiente em escala devido aos altos custos computacionais.”
(“During fine-tuning, some neural network layers can be frozen to reduce training complexity, this approach still falls short at scale due to high computational costs.”)— Autor Desconhecido, Expert em AI
Treinamento e otimização
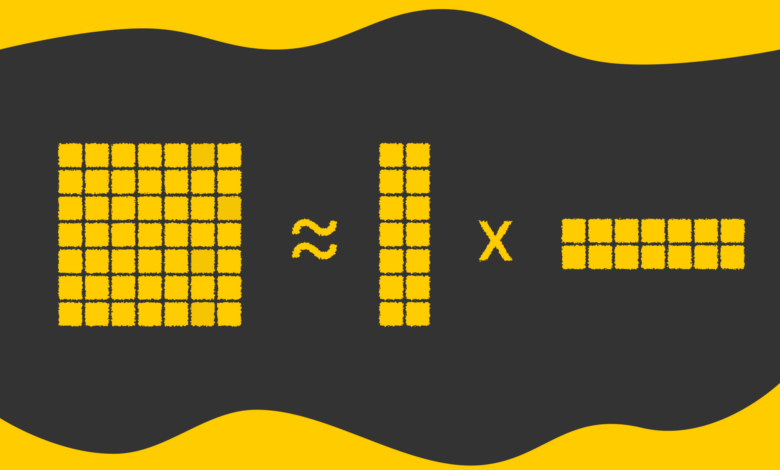
A técnica de Low-Rank Adaptation (LoRA) se destaca como uma solução para mitigar o impacto computacional do fine-tuning. Ao fatorar uma grande matriz de pesos em duas matrizes menores, LoRA reduz significativamente os parâmetros treináveis, mantendo o poder do modelo intacto. Por exemplo, uma matriz de peso de 8192 x 8192 pode ser representada por duas matrizes de dimensões 8192 x 8 e 8 x 8192, o que resulta em um total de cerca de 131K parâmetros — muito menos que os 67M originais.
“Nesta abordagem, tratamos Wx como o conhecimento prévio do grande modelo e interpretamos ΔWx = BAx como o conhecimento específico da tarefa introduzido durante o fine-tuning.”
(“In LoRA optimization, we treat Wx as the prior knowledge of the large model and interpret ΔWx = BAx as task-specific knowledge introduced during fine-tuning.”)— Autor Desconhecido, Expert em AI
Resultados e métricas
Além de LoRA, a técnica QLoRA integra a quantização no processo, permitindo que os pesos da rede neural sejam armazenados com menos bits, como de 32 para 16 bits. Isso resulta em uma economia adicional de espaço sem perda significativa de desempenho. Essa combinação de técnicas não apenas acelera o treinamento, mas também abre possibilidades para adaptar modelos a uma variedade de tarefas com um custo computacional reduzido e uma eficiência aprimorada.
À medida que essas técnicas avançam, elas prometem impactar setores que vão da assistência virtual a sistemas de recomendação, permitindo que um único modelo seja adaptado a múltiplas aplicações.
Próximas etapas na pesquisa podem incluir a exploração de prefix-tuning, que se integra diretamente nas camadas de atenção do modelo, trazendo outra dimensão de eficiência no treinamento de modelos amplos.
Fonte: (Towards Data Science – AI, ML & Deep Learning)

































