LLMs melhoram personalização com fine-tuning e aprendizado contextual
São Paulo — InkDesign News — Pesquisadores da Google DeepMind e da Universidade de Stanford investigaram as capacidades de generalização de dois métodos de personalização de modelos de linguagem grandes (LLMs) — fine-tuning e aprendizado em contexto (ICL). O estudo sugere que o ICL oferece maior capacidade de generalização, embora com custos computacionais mais elevados durante a inferência.
Tecnologia e abordagem
O fine-tuning consiste em ajustar um LLM pré-treinado em um conjunto de dados menor e especializado, modificando seus parâmetros internos. Em contraste, o ICL não altera os parâmetros do modelo; em vez disso, utiliza exemplos do desempenho desejado inseridos diretamente no prompt de entrada. O modelo então aplica esses exemplos para resolver novas consultas semelhantes.
Os pesquisadores desenvolveram conjuntos de dados sintéticos controlados para testar como os modelos se comportam ao generalizar para novas tarefas. Para evitar coincidências com os dados que os LLMs encontraram durante o pré-treinamento, todos os substantivos, adjetivos e verbos foram substituídos por termos fictícios.
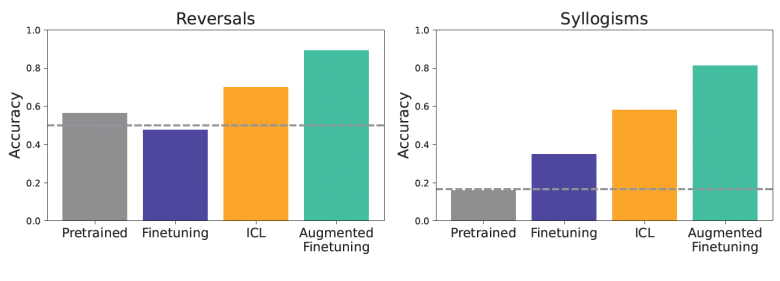
Aplicação e desempenho
Os testes incluíram desafios de generalização, como inversões simples e silogismos, para avaliar a capacidade do modelo de deduzir novas informações. De acordo com os resultados, o ICL demonstrou melhor desempenho em situações de generalização, especialmente em tarefas que envolvem reversões ou deduções lógicas. Modelos pré-treinados, sem fine-tuning ou ICL, apresentaram desempenho insatisfatório, evidenciando a dificuldade imposta pela novidade dos dados de teste.
“Um dos principais trade-offs a considerar é que, embora o ICL não exija fine-tuning, que economiza custos de treinamento, ele é geralmente mais computacionalmente caro a cada uso, pois requer fornecer contexto adicional ao modelo.”
(“One of the main trade-offs to consider is that, whilst ICL doesn’t require fine-tuning (which saves the training costs), it is generally more computationally expensive with each use, since it requires providing additional context to the model.”)— Andrew Lampinen, Cientista de Pesquisa, Google DeepMind
Impacto e mercado
Os pesquisadores propuseram uma nova abordagem de fine-tuning que inclui inferências em contexto. Essa estratégia combina as capacidades de ICL com dados de fine-tuning existentes para gerar exemplos mais diversos. O uso de estratégias de aumento de dados, como a estratégia local (geração de inversões de frases individuais) e a estratégia global (uso de todo o conjunto de dados como contexto), resultou em melhorias significativas no desempenho.
Modelos que foram fine-tunados com esses conjuntos de dados aumentados superaram não apenas o fine-tuning padrão, mas também o ICL simples. Essa abordagem pode beneficiar aplicações empresariais que requerem modelos mais robustos em cenários do mundo real, equilibrando a economia de custos com a necessidade de alta generalização.
“Os resultados sugerem que ICL e fine-tuning aumentado serão mais eficazes ao capacitar o modelo a responder perguntas relacionadas.”
(“our results suggest that ICL and augmented fine-tuning will be more effective at enabling the model to answer related questions.”)— Andrew Lampinen, Cientista de Pesquisa, Google DeepMind
Os próximos passos incluem a exploração mais profunda de como esses métodos interagem em diferentes cenários. A pesquisa sugere que o fine-tuning aumentado pode se tornar uma prática comum em empresas que enfrentam limitações de desempenho com métodos tradicionais.
Fonte: (VentureBeat – AI)

































