LLM acelera execução em dispositivos com transformadores escaláveis
São Paulo — InkDesign News —
Pesquisas recentes em machine learning revelam avanços significativos na execução de grandes modelos de linguagem (LLMs) em dispositivos locais, reduzindo a dependência de servidores poderosos e infraestrutura em nuvem.
Contexto da pesquisa
Um grupo de pesquisa da Universidade Sejong desenvolveu uma solução de hardware inovadora, publicada na revista Electronics, chamada Unidade Aceleradora de Transformadores Escalável (STAU). Esta tecnologia visa permitir a execução eficiente de diversos modelos baseados em transformadores em sistemas embutidos, destacando-se por sua adaptatividade a diferentes tamanhos de entrada e estruturas de modelo.
Método proposto
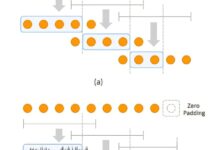
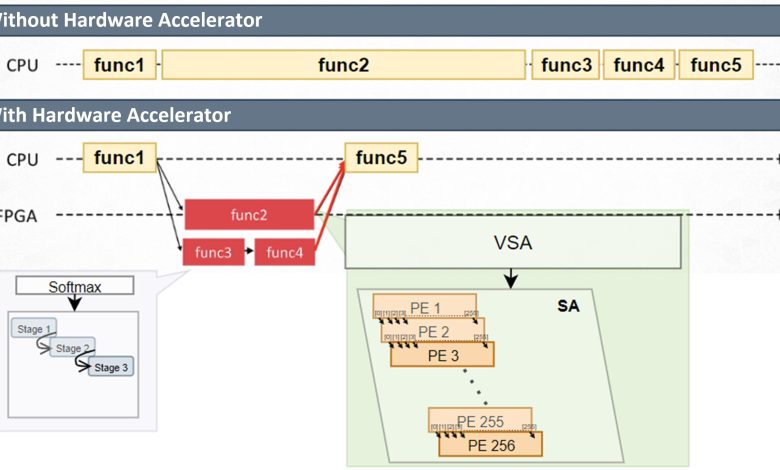
O STAU é fundamentado em uma arquitetura chamada Matriz Sistólica Variável (VSA), que otimiza operações matriciais, essenciais para modelos de transformadores, de forma que se adapta ao comprimento da sequência de entrada. O sistema alimenta os dados linha por linha e carrega pesos em paralelo, reduzindo interrupções de memória e melhorando a taxa de transferência.
Além disso, o time reengenheirou a função softmax, frequentemente um ponto de estrangulamento, usando uma abordagem Radix-2 que baseia-se em operações de deslocamento e adição. Isso diminui a complexidade do hardware sem comprometer a qualidade dos resultados. O STAU utiliza também um formato customizado de ponto flutuante de 16 bits, otimizado para cargas de trabalho de transformadores.
Resultados e impacto
Nos testes de benchmark, a aceleradora apresentou um aumento de 3,45 vezes na velocidade em comparação com a execução apenas por CPU, mantendo mais de 97% de precisão numérica e reduzindo o tempo total de computação em mais de 68% ao processar sequências mais longas. Testes internos recentes mostraram uma melhoria adicional, alcançando um aumento de até 5,18 vezes, destacando a escalabilidade a longo prazo da arquitetura.
“A arquitetura STAU demonstra que modelos de transformadores, mesmo os grandes, podem ser viáveis para aplicações em dispositivos locais”
(“The STAU architecture shows that transformer models, even large ones, can be made practical for on-device applications.”)— Seok-Woo Chang, Autor Principal, Universidade Sejong
A implementação do STAU foi realizada em um FPGA Xilinx (VMK180) e controlada por um processador Arm Cortex-R5 embutido. Essa abordagem híbrida possibilita o suporte a uma gama de modelos transformadores, permitindo atualizações simples de software sem modificações de hardware.
O avanço desta tecnologia promete tornar modelos de linguagem avançados mais acessíveis em dispositivos móveis, wearables e sistemas de computação de borda, onde a execução de IA em tempo real, privacidade e baixa latência são fundamentais.
Fonte: (TechXplore – Machine Learning & AI)