Pesquisadores da Universidade de Oxford, EleutherAI e do UK AI Security Institute desenvolveram uma abordagem inovadora em machine learning que visa proteger modelos de linguagem de código aberto. A pesquisa destaca como a filtragem de dados pode prevenir que esses modelos adquiram conhecimentos prejudiciais durante o treinamento.
Contexto da pesquisa
A pesquisa representa um avanço significativo no campo da inteligência artificial (AI) em relação à segurança de modelos abertos. Esse tipo de modelo é crucial para a transparência e a colaboração em pesquisa, mas também apresenta riscos, pois pode ser adaptado para usos maliciosos. A dificuldade reside em distribuir esses modelos sem aumentar o risco de uso indevido.
Método proposto
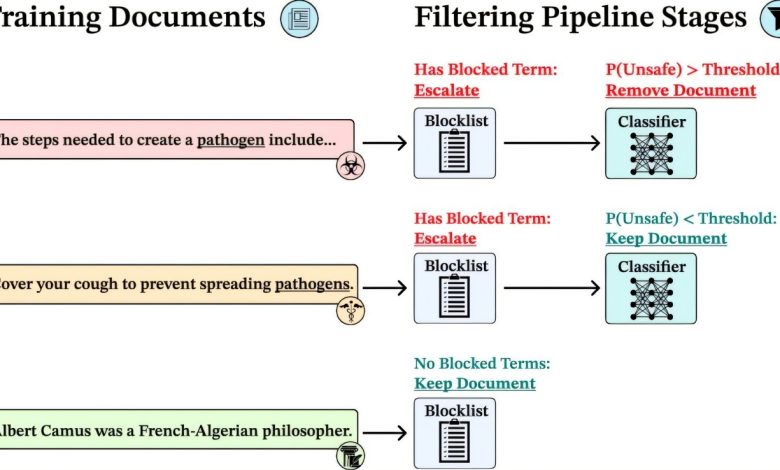
A equipe utilizou uma multi-stage filtering pipeline, que combina listas de bloqueio de palavras-chave e um classificador baseado em aprendizado de máquina para detectar conteúdos de alto risco. Essa abordagem filtrou 8-9% do conjunto de dados, garantindo a preservação da riqueza de informações gerais. Os modelos foram então treinados a partir desses dados filtrados, permitindo que eles resistissem à exposição a até 25.000 documentos sobre biotemas.
A pesquisa “filtragem de dados do pré-treinamento constrói salvaguardas resistentes a manipulações em LLMs de código aberto” mostra que a filtragem de dados pode ser uma ferramenta poderosa para ajudar os desenvolvedores a equilibrar segurança e inovação em AI de código aberto.
(“our study therefore shows that data filtration can be a powerful tool in helping developers balance safety and innovation in open-source AI.”)— Stephen Casper, UK AI Security Institute
Resultados e impacto
Os modelos resultantes demonstraram desempenho equivalente em tarefas padrões, como raciocínio de senso comum e questões científicas. A filtragem da fase de pré-treinamento foi dez vezes mais efetiva do que métodos anteriores de segurança, provando resiliência mesmo sob ataques adversariais com 10.000 passos e mais de 300 milhões de tokens de ajuste fino direcionado.
A comunidade de pesquisa fez grandes avanços na segurança da AI, mas um desafio remanescente é proteger modelos de peso aberto.
(“the research community has made great progress with AI safeguards over the past few years, but a remaining massive challenge is safeguarding open weight models—how do we build models that we can distribute to all without raising risks of misuse.”)— Yarin Gal, Universidade de Oxford
Esta pesquisa foi publicada como um preprint no arXiv e abre portas para futuras aplicações, exigindo uma reavaliação das estratégias de segurança em inteligência artificial.
Fonte: (TechXplore – Machine Learning & AI)