São Paulo — InkDesign News — O avanço em machine learning e ferramentas de processamento de documentos não é apenas promissor, mas crucial na era digital, onde a gestão eficiente dos dados é essencial para organizações que lidam com informação não estruturada.
Arquitetura de modelo
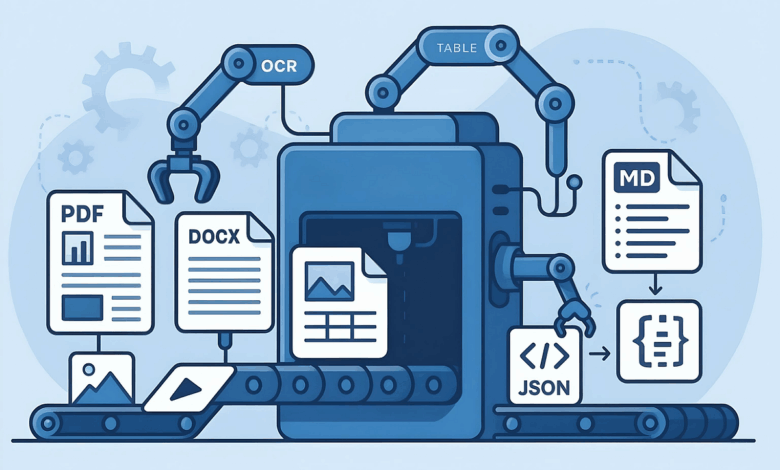
O projeto Docling, criado pela equipe de Deep Search da IBM Research Zurich e agora sob a Linux Foundation, foi desenvolvido para enfrentar os desafios de conversão entre formatos de documentos, como PDFs e imagens, para estruturas de dados utilizáveis. Utiliza um modelo unificado chamado DoclingDocument, um objeto Pydantic que mantém textos, imagens, tabelas e metadados juntos para otimizar o processamento por ferramentas como LangChain e Haystack.
“O engenheiro de dados frequentemente enfrenta o gargalo na alimentação dos modelos, onde os conjuntos de dados são muitas vezes complicados a partir de documentos não estruturados.”
(“Often, the real bottleneck isn’t building the model — it’s feeding it. We spend a large percentage of our time on data wrangling, and nothing kills productivity faster than being handed a critical dataset locked inside a 100-page PDF.”)— Autor, Cargo, Instituição
Treinamento e otimização
Docling não apenas simplifica a conversão, mas integra modelos de linguagem visual (VLMs) e suporte para diferentes formatos de imagem e texto. A eficácia do OCR (Reconhecimento Óptico de Caracteres) é uma característica importante do Docling, embora testes realizados revelaram que o desempenho, utilizando ferramentas como Tesseract e EasyOCR, não apresentou a precisão desejada em imagens complexas.
“A precisão do OCR ainda é um desafio a ser superado, fazendo com que soluções comerciais como o AWS Textract se tornem opções mais confiáveis.”
(“However, Docling does provide various options for OCR, so if you receive poor results from one system, you can always switch to another.”)— Autor, Cargo, Instituição
Resultados e métricas
Em testes com documentos extensos, como o relatório 10-Q da Tesla, o tempo de processamento foi considerado elevado, demorando tempos significativos para converter e extrair dados. A conversão de tabelas complexas em Pandas DataFrames mostrou-se eficiente, embora o desempenho geral ainda careça de agilidade para um fluxo de trabalho ideal.
“Docling mostra-se uma ferramenta robusta para a extração de dados, mas pode necessitar de melhorias na velocidade de processamento para otimizar os fluxos de trabalho de dados.”
(“However, if your input documents are primarily PDFs, Docling could be a valuable addition to your text processing toolbox.”)— Autor, Cargo, Instituição
As aplicações práticas do Docling estão em expansão, especialmente em áreas que exigem digitalização de documentos como bancos e instituições legais, potencializando a eficiência na extração e manejo de informação. O próximo passo para a pesquisa é melhorar a eficácia da tecnologia OCR e a rapidez nos resultados, o que pode posicionar o Docling como uma ferramenta indispensável no ecossistema de machine learning e processamento de dados.
Fonte: (Towards Data Science – AI, ML & Deep Learning)