São Paulo — InkDesign News —
Um novo sistema de comunicação coletiva, OptiReduce, desenvolvido na Universidade de Michigan, acelera o treinamento de modelos de machine learning e AI distribuídos em múltiplos servidores na nuvem, ao impor limites de tempo para comunicação entre os servidores, em vez de esperar que todos estejam sincronizados para avançar.
Contexto da pesquisa
O crescimento dos modelos de AI e machine learning exige o uso de servidores distribuídos para treinamento em deep learning. No entanto, centros de computação em nuvem enfrentam congestionamentos e atrasos causados pelo compartilhamento intenso de recursos, criando gargalos que retardam o processo. Até então, os sistemas distribuídos de deep learning necessitavam de comunicação perfeita e confiável entre servidores, o que causava lentidão pela espera dos servidores mais lentos (stragglers).
Método proposto
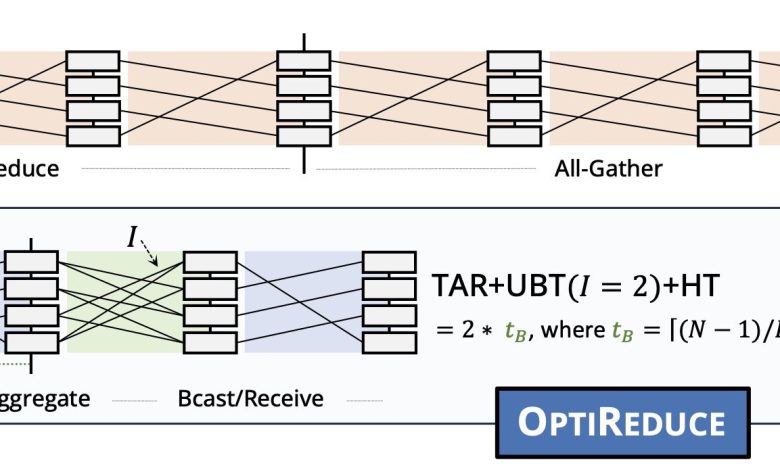
O OptiReduce rompe com a exigência de comunicação perfeita ao introduzir limites de tempo adaptáveis para a comunicação entre servidores, acelerando a convergência dos modelos mesmo com perda parcial de dados. Quando a rede está mais ociosa, os limites de tempo são reduzidos; quando a rede está mais ocupada, são estendidos. Os dados perdidos nas timeouts são aproximados por técnicas matemáticas, aproveitando a resiliência inerente dos modelos de deep learning. Segundo Muhammad Shahbaz, professor da U-M, a abordagem é comparada à transição dos CPUs gerais para GPUs específicas para melhorar eficiência:
“Estamos redefinindo a pilha computacional para AI e machine learning ao desafiar a necessidade de 100% de confiabilidade exigida em cargas tradicionais. Ao aceitar uma confiabilidade limitada, as cargas de machine learning rodam significativamente mais rápido sem comprometer a acurácia.”
(“We’re redefining the computing stack for AI and machine learning by challenging the need for 100% reliability required in traditional workloads. By embracing bounded reliability, machine learning workloads run significantly faster without compromising accuracy.”)— Ertza Warraich, estudante de doutorado, Purdue University
Resultados e impacto
Testado em clusters virtuais e na plataforma CloudLab, o OptiReduce alcançou até 70% de redução no tempo para atingir a acurácia-alvo comparado ao Gloo, e 30% em relação ao NCCL na nuvem compartilhada. Experimentos mostraram que até 5% de perda de dados em timeouts não afetam a performance dos modelos, especialmente em modelos maiores como Llama 4, Mistral 7B, Falcon, Qwen e Gemini, enquanto modelos menores são mais sensíveis a perdas.
A equipe prevê evolução do método, migrando da camada de software para implementações em hardware nos controladores de rede (NICs), visando taxas de transferência na ordem de centenas de Gigabits por segundo. Esta pesquisa representa um avanço que pode redefinir a comunicação em sistemas de deep learning distribuídos, acelerando o treinamento em ambientes complexos de nuvem.
Fonte: (TechXplore – Machine Learning & AI)

































