São Paulo — InkDesign News —
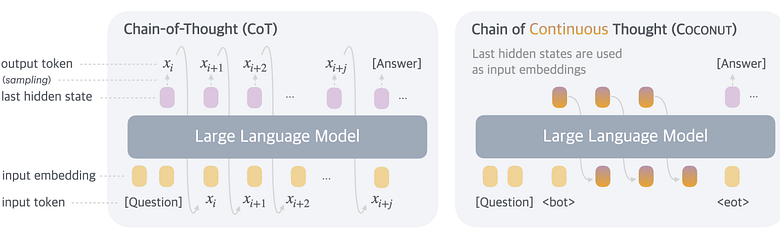
Um novo enfoque em “machine learning” foi apresentado por pesquisadores da Meta, defendendo que a transição do raciocínio nas redes neurais a partir do “Chain-of-Thought” (CoT) para representações latentes pode ampliar a capacidade dos modelos de linguagem para resolver problemas complexos.
Arquitetura de modelo
O modelo, denominado Chain of Continuous Thought (Coconut), modifica a forma como os modelos preveem resultados. Em vez de depender de tokens textuais finais, o Coconut utiliza as últimas representações latentes do espaço contínuo do modelo. Dessa forma, ele opera em dois modos: “Modo Linguagem” e “Modo Latente”. No Modo Linguagem, o modelo processa tokens textuais, enquanto no Modo Latente, ele utiliza estados ocultos internos. A capacidade de alternar entre esses modos é fundamental para a eficiência do treinamento.
As adaptações propostas buscam remover a dependência do input textual, usando os estados ocultos como novas entradas, permitindo o treinamento contínuo de um raciocínio mais abstrato e matemático. A abordagem ainda é controlada por tokens especiais que definem quando mudar de modo.
Treinamento e otimização
A metodologia inclui um currículo de treinamento em múltiplas etapas, onde a introdução gradual de raciocínios latentes permite ao modelo decompor os problemas em tarefas mais simples, facilitando a internalização do processo de raciocínio. Os pesquisadores destacam que a substituição progressiva de passos de raciocínio textual por passos latentes gera um aumento significativo na eficácia do modelo.
O experimento foi realizado em três conjuntos de dados, sendo GSM8K um dos principais, focando em desafios de raciocínio matemático e lógico.
Resultados e métricas
As análises mostraram que o Coconut superou o CoT em tarefas de raciocínio lógico, com uma acurácia de 97,0% no ProsQA, em comparação aos 77,5% do CoT. No entanto, essa abordagem trouxe uma diminuição de precisão em GSM8K, onde o Coconut alcançou 34,9% contra 42,9% do CoT. Essa discrepância pode ser atribuída à natureza matemática deste conjunto de dados, que requer menos raciocínio.
A comparação com outros modelos também apresentou vantagens do Coconut, destacando a importância do currículo de múltiplas etapas no aumento do desempenho de aprendizado. Estratégias como Pause as Thought demonstraram resultados inferiores quando comparadas ao modelo Coconut, corroborando a hipótese de que a introdução de raciocínios latentes aumenta a eficiência do treinamento.
Conforme os pesquisadores exploram a representação latente, as aplicações práticas em raciocínios mais complexos e o desenvolvimento de modelos de machine learning não focados em sintaxe de linguagem se tornam promissores, abrindo novas fronteiras para a pesquisa em inteligência artificial.
Fonte: (Towards Data Science – AI, ML & Deep Learning)