CNNs e Vision Transformers classificam pólen com inteligência artificial
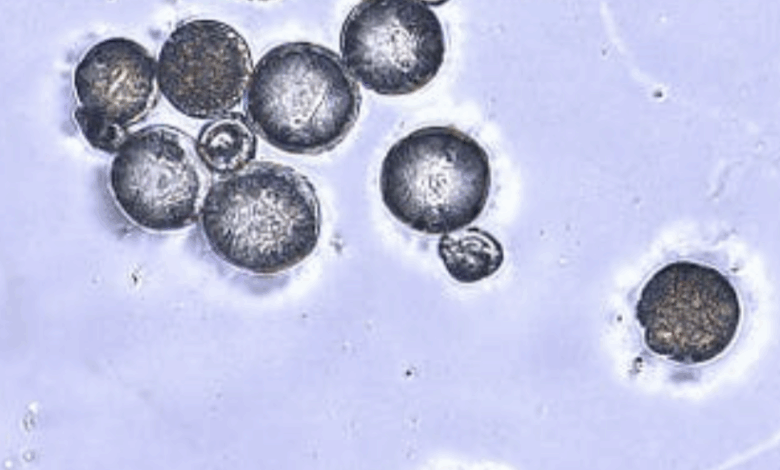
São Paulo — InkDesign News — A classificação visual de grãos de pólen, uma tarefa desafiadora no campo do machine learning, avança com novos modelos de aprendizado profundo. Estudo recente propõe a utilização de redes neurais convolucionais (CNNs) e transformadores de visão para melhorar a precisão na identificação de diferentes espécies.
Arquitetura de modelo
Os pesquisadores desenvolveram um conjunto de dados exclusivo com 200 imagens de grãos de pólen de quatro espécies comuns de plantas frutíferas. Para otimização do modelo, eles utilizaram transfer learning com arquiteturas pré-treinadas, como ResNet50 e ResNet152. Além disso, o Vision Transformer (ViT) foi implementado, sendo conhecido por sua eficácia em tarefas de visão computacional.
“O modelo provou detectar polens com alta precisão, mas havia que considerar a confiança do modelo.”
(“The model proved to detect pollens with very high accuracy, but there was one more thing to consider: the model’s confidence.”)— Antoni Olbrysz, Autor
A quantidade de imagens e a qualidade das mesmas foram cruciais para o sucesso na classificação. Cada classe possui 200 imagens de fragmentos de pólen, utilizando imagens sem coloração para não interferir nos resultados do classificador.
Treinamento e otimização
O treinamento foi realizado utilizando o modelo YOLOv12, que demonstrou ser eficiente mesmo em conjuntos de dados menores. Os pesquisadores etiquetaram manualmente 10 imagens de cada classe antes de dividir os dados em conjuntos de treinamento e validação. Eles exploraram dois limiares de confiança, 0.8 e 0.9, para avaliar o impacto nas métricas de desempenho.
“Esses modelos apresentaram desempenho variado, com alguns oferecendo resultados medianos, enquanto outros se destacaram com métricas de alto nível.”
(“The classical models exhibited varied performance levels – some performed worse than expected, whereas others delivered fairly good metrics.”)— Karol Struniawski, Autor
O impacto dessas decisões foi evidente nas análises estatísticas realizadas. As métricas de desempenho foram monitoradas, utilizando a matriz de confusão e GradCAM para avaliar as predições visuais do modelo.
Resultados e métricas
As redes neurais convolucionais mostraram resultados promissores, com as arquiteturas ResNet50 e ResNet152 alcançando uma pontuação F1 superior a 99% em uma das configurações de teste. Em comparação, o Vision Transformer alcançou resultados semelhantes, mas com uma pontuação perfeita em um dos conjuntos de dados.
“O uso de transformadores de visão levou a um desempenho quase perfeito, superando modelos anteriores em termos de acurácia.”
(“The use of Vision Transformers led to near-perfect performance, surpassing previous models in terms of accuracy.”)— Tomasz Wierzbicki, Autor
Essas descobertas destacam a eficácia do aprendizado profundo na classificação de imagens, mostrando como essas tecnologias podem ser aplicadas em áreas como biotecnologia e ecologia.
As implicações práticas dessas inovações vão além da simples classificação; os modelos têm o potencial de contribuir significativamente para estudos de polinização e monitoramento ambiental. A pesquisa poderá ser expandida para incluir mais espécies e outras aplicações em aprendizado de máquina.
Fonte: (Towards Data Science – AI, ML & Deep Learning)