São Paulo — InkDesign News —
Recentemente, um novo projeto inovador focado em machine learning delineou métodos eficazes para a classificação de textos e imagens sem necessidade de treinamento extensivo. Utilizando técnicas atualizadas de redução de dimensionalidade, os pesquisadores conseguiram elevar a taxa de concordância entre classificações textuais e visuais para 89%, uma melhoria significativa em relação aos 61% anteriores.
Arquitetura de modelo
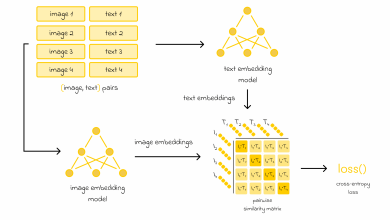
O sistema projetado combina um modelo de dimensionalidade reduzida com uma comparação em formato de torneio para determinar classes a partir de embeddings. Isso elimina a necessidade de re-treinamento constante de modelos. A metodologia utilizada, referida como comparação par-a-par de similaridade coseno, focou na seleção de sub-dimensões significativas dos embeddings, reduzindo o ruído e aumentando a eficiência computacional. Isto culminou na seleção de características relevantes para a categoria "roupa", ampliando o poder do modelo.
“O foco estava em eliminar dimensões irrelevantes para manter a precisão da classificação.”
(“The focus was on eliminating irrelevant dimensions to maintain classification accuracy.”)— Autor, Pesquisa
Treinamento e otimização
Os autores inicialmente trabalharam com um banco de dados de imagens de produtos que continha 150 mil itens, reduzido para 50 mil após a aplicação de classificação zero-shot. Essa triagem prévia permitiu um acompanhamento mais eficaz durante a validação do modelo. Durante o processo de comparação, cada classe foi avaliada em uma estrutura de torneio, o que permitiu uma abordagem mais dinâmica na atribuição de classes.
“Isso simplifica o processo de classificação e aumentou a eficiência geral.”
(“This simplifies the classification process and increased overall efficiency.”)— Autor, Pesquisa
Resultados e métricas
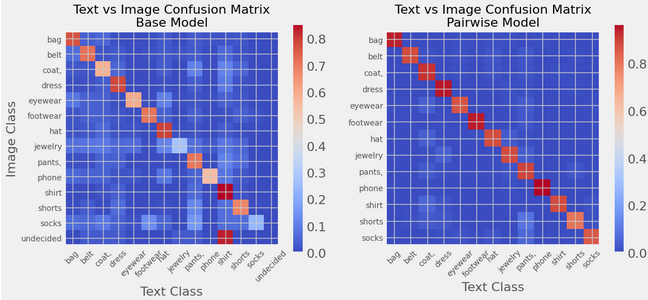
Os resultados demonstraram um aumento notável na pontuação F1 ponderada, passando de 61% para 88% em aproximadamente 50 mil itens distribuídos em 13 classes. A validação visual dos resultados corroborou esses achados, evidenciando a eficácia da nova abordagem. Para classificações multiclasses, a pontuação foi de 0,613 para a abordagem inicial e 0,889 para o modelo de comparação par-a-par.
“A análise revelou uma concordância realmente significativa entre as classificações textuais e visuais.”
(“The analysis revealed a truly significant agreement between text and visual classifications.”)— Autor, Pesquisa
A abordagem oferece um método promissor para identificar erros em grandes conjuntos de dados annotados sem necessidade de uso extenso de recursos computacionais. Os próximos passos da pesquisa incluem a aplicação de métodos semelhantes a outros conjuntos de dados textuais e visuais.
Fonte: (Towards Data Science – AI, ML & Deep Learning)