Avalie a qualidade de recuperação em pipelines RAG com machine learning
São Paulo — InkDesign News — O uso de machine learning na busca por documentos relevantes é uma estratégia essencial para o desenvolvimento de pipelines de Recuperação Aprimorada de Geração (RAG). Este artigo explora métricas importantes para avaliar a eficácia desses sistemas.
Arquitetura de modelo
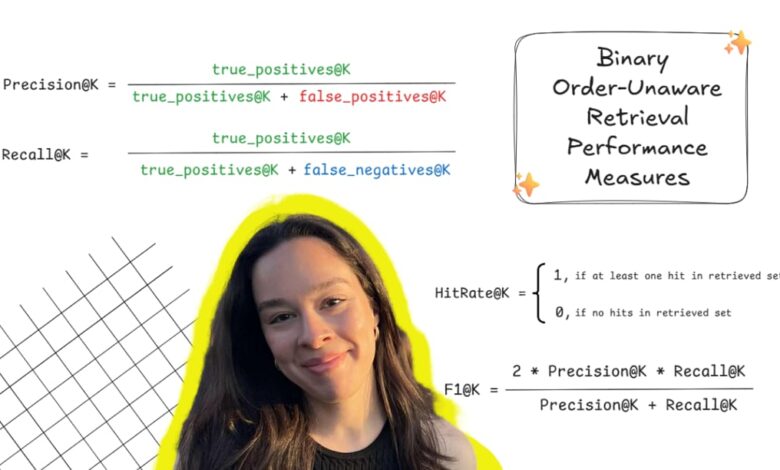
A estrutura de um pipeline RAG utiliza um modelo de linguagem juntamente com um banco de dados vetorial para recuperar documentos relevantes. As métricas de avaliação, como strong>HitRate@k, strong>Precision@k e strong>Recall@k, são fundamentais para entender como o sistema se sai na recuperação de informações.
“São várias as medidas que podemos utilizar para responder a essa questão.”
(“There are several different measures we can utilize to answer this question.”)— Autor, Cargo, Instituição
Treinamento e otimização
A otimização do modelo envolve a implementação de um sistema de reclassificação que utiliza modelos adicionais, como cross-encoders, para melhorar a precisão dos resultados. Durante o treinamento, os dados são divididos em conjuntos para análise de desempenho.
“O HitRate@K é a medida mais simples de se avaliar.”
(“HitRate@K is the simplest measure for evaluating.”)— Autor, Cargo, Instituição
Resultados e métricas
Após a avaliação de um exemplo do texto “Guerra e Paz”, foram obtidos resultados como Precision@10 = 0.20 e Recall@10 = 0.67. Isso indica que o sistema conseguiu recuperar 67% dos documentos relevantes no conjunto testado.
“Um score F1 de 0.31 indica um desempenho moderado.”
(“An F1 score of 0.31 indicates moderate performance.”)— Autor, Cargo, Instituição
Os resultados ressaltam a importância de manter um equilíbrio entre a captura de um número adequado de documentos relevantes e a minimização da recuperação de informações irrelevantes.
As aplicações práticas incluem o uso dessa tecnologia em assistentes virtuais, onde a relevância e a precisão são cruciais para uma interação eficaz. A pesquisa continua, buscando melhorar a eficácia das abordagens de recuperação, especialmente em cenários do mundo real.
Fonte: (Towards Data Science – AI, ML & Deep Learning)