São Paulo — InkDesign News — Recentemente, a área de machine learning tem se concentrado na avaliação do desempenho de Modelos de Linguagem de Grande Escala (LLMs), ressaltando desafios significativos na busca por ferramentas confiáveis para tarefas específicas.
Arquitetura de modelo
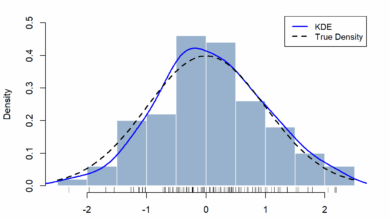
A tarefa de avaliar um LLM é similar àquelas enfrentadas por profissionais no campo do machine learning: definir o que constitui uma resposta bem-sucedida e desenvolver uma maneira de mensurá-la quantitativamente. No entanto, essa tarefa apresenta variações significativas, especialmente quando um modelo produz texto em comparação com a produção de números ou probabilidades.
“Na aprendizagem clássica de máquina, basicamente tudo que muda sobre a saída levará o resultado mais perto do correto ou mais longe.”
(“In classical machine learning, basically anything that changes about the output will take the result either closer to correct or further away.”)— Autor Desconhecido
Treinamento e otimização
Os critérios de avaliação são cruciais para distinguir entre respostas aceitáveis e aquelas que falham. Como em uma avaliação acadêmica, desenvolver um conjunto de critérios claros é essencial. A utilização de rubricas ajuda a minimizar biases durante o processo, possibilitando uma avaliação mais objetiva. Essa abordagem também pode ser adaptada para o uso de LLMs, onde a avaliação é feita comparando a resposta gerada com um conjunto de “respostas verdadeiras” previamente elaboradas.
“Se você não pode determinar o que define uma resposta bem-sucedida, então eu sugiro fortemente que considere se um LLM é a escolha certa para esta situação.”
(“If you can’t determine what defines a successful answer, then I strongly suggest you consider whether an LLM is the right choice for this situation.”)— Autor Desconhecido
Resultados e métricas
A avaliação do desempenho dos LLMs pode ser feita utilizando outros LLMs como ferramentas de mensuração. Ferramentas como DeepEval permitem estruturar essa avaliação de acordo com critérios específicos, promovendo uma análise precisa do output gerado.
Entretanto, é fundamental reconhecer que os LLMs não são adequados para julgar a veracidade ou precisão dos fatos. “Os LLMs não têm um framework para distinguir entre fato e ficção; eles apenas compreendem a linguagem de forma abstrata.”, conforme notado por especialistas na área.
As aplicações práticas deste tipo de avaliação são grandes e variam desde a produção de resumos de documentos até a criação de chatbots eficientes. À medida que a tecnologia avança, a necessidade por metodologias rigorosas de avaliação só tende a crescer. Pesquisas futuras poderão focar em integrar diferentes ferramentas para aprimorar a confiabilidade e eficácia dos LLMs.
Fonte: (Towards Data Science – AI, ML & Deep Learning)