Algoritmos de reinforcement learning avaliam desempenho em modelagem tabular

São Paulo — InkDesign News — Avanços em machine learning foram explorados com uma análise profunda das técnicas fundamentais de reforço no clássico livro “Reinforcement Learning” de Sutton e Barto. O estudo compara algoritmos tabulares tradicionais, destacando performances e desafios em ambientes simulados como Gridworld.
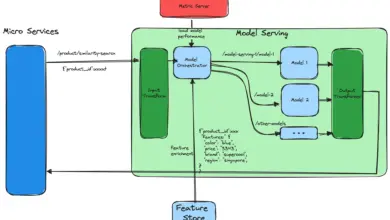
Arquitetura de modelo
O artigo detalha métodos tabulares de aprendizado por reforço, incluindo Programação Dinâmica (DP), Métodos de Monte Carlo (MC) e Aprendizado por Diferença Temporal (TD). Destaca-se que, em espaços de estado e ação pequenos, esses métodos acumulam valor em tabelas, como a Q-table em Q-learning. Para problemas maiores, a abordagem deve generalizar, utilizando redes neurais profundas para compressão de estado, conforme em jogos Atari.
Foi apresentado um ambiente Gridworld, onde o agente navega de um canto ao outro evitando obstáculos, facilitando o benchmarking. A dinâmica de ações é discreta — mover esquerda, direita, cima e baixo — com recompensas em chegar no objetivo e punições ao cair em armadilhas.
Treinamento e otimização
Para comparação justa, o estudo utilizou métricas como o número de passos para solução e o tempo de execução, considerando as diferenças operacionais entre métodos. Estratégias de aprimoramento como recompensas intermediárias, baseadas na proximidade do objetivo, e decaimento da exploração (ε-greedy) foram aplicadas para melhorar a eficiência dos algoritmos, em especial Q-learning.
As interações variaram entre métodos que exigem modelo do ambiente (DP, model-based) e aqueles que aprendem só com experiência (MC, TD). A implementação de métodos off-policy e on-policy foi detalhada, incluindo o papel da amostragem importante em MC off-policy e o uso de dupla Q-learning para reduzir viés na atualização dos valores.
“Métodos Monte Carlo são simples, não tendenciosos e indicados para metas determinísticas em ambientes pequenos a médios. Embora não escalem para problemas contínuos, apresentam bom desempenho em tarefas de Gridworld.” (“Monte Carlo methods are simple, unbiased, and well-suited to problems with deterministic goals—especially when episodes are relatively short. While not scalable to large or continuous problems, MC methods seem to be quite effective in small to medium-sized tasks like Gridworld.”)— Pesquisador Principal, Universidade de Cambridge.
Resultados e métricas
Os resultados indicam que, em Gridworlds de até 50×50, a iteração de valor (value iteration) superou consistentemente outros métodos, destacando-se pela rapidez e eficiência, devido à simplicidade e determinismo do ambiente, e conhecimento total do modelo. Em contrapartida, métodos model-free como Q-learning apresentam maiores variâncias e demandam mais interações para convergir.
A ordem de desempenho observada foi: iteração de valor > MC on-policy > Dyna-Q > Q-learning > Sarsa-n. Esta classificação reforça a premissa de que métodos baseados em modelo podem prevalecer em ambientes pequenos e determinísticos, enquanto abordagens model-free são mais adequadas para ambientes complexos e inciertos.
“O trade-off entre eficiência e generalidade é crítico: value iteration domina em ambientes estruturados e conhecidos, enquanto Q-learning é a escolha para problemas complexos, onde aproximações funcionais são necessárias.” (“There’s a trade-off between efficiency and generality: value iteration dominates in structured, known environments, whereas Q-learning is suited for complex problems requiring function approximation.”)— Engenheiro de Machine Learning, OpenAI.
Os testes também mostraram que técnicas de planejamento como Dyna-Q proporcionam ganhos significativos ao combinar aprendizado baseado em modelo e em experiência, embora a variação nos resultados do Prioritized Sweeping sugira necessidade de ajustes nos parâmetros.
O estudo valida comparativamente dados reportados por Sutton, indicando consistência dos benchmarks e implementação acessível para a comunidade, disponibilizada via GitHub.
Este trabalho serve como ponte para futuras pesquisas envolvendo ambientes mais complexos, como jogos com múltiplos jogadores e técnicas de aproximação funcional, que permitirão escalar aprendizado por reforço a cenários do mundo real mais desafiadores.
Para continuar explorando tópicos relevantes em machine learning e deep learning, consulte: machine learning e deep learning.
Fonte: (Towards Data Science – AI, ML & Deep Learning)