AI pode comprometer a qualidade da pesquisa em machine learning
Pesquisas relacionadas a machine learning e inteligência artificial (AI) têm avançado significativamente, mas novas evidências sugerem que a qualidade da pesquisa pode estar sendo comprometida. Um estudo da Universidade de Surrey alerta para os riscos associados ao uso indiscriminado dessas tecnologias.
Contexto da pesquisa
Um grupo de pesquisadores da Universidade de Surrey analisou publicações que associam preditores a condições de saúde, utilizando um banco de dados do governo americano chamado National Health and Nutrition Examination Survey (NHANES). Este dataset é amplamente utilizado na pesquisa sobre relações entre condições de saúde, estilo de vida e resultados clínicos.
Método proposto
O estudo, publicado na revista PLOS Biology, sugere que muitos trabalhos recentes têm adotado uma abordagem superficial na análise de dados, frequentemente focando em variáveis únicas e ignorando explicações multifatoriais. Além disso, os pesquisadores recomendam a implementação de revisões por pares mais rigorosas e a inclusão de revisores com expertise estatística para avaliar estudos que utilizem conjuntos de dados complexos.
Resultados e impacto
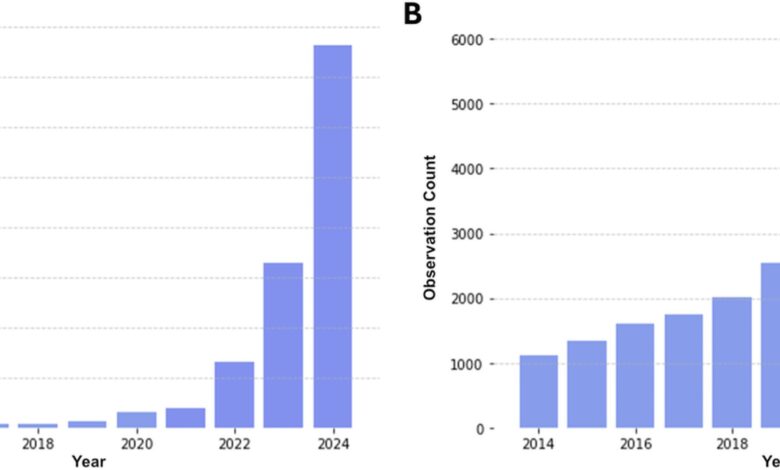
Os autores descobriram que, entre 2014 e 2021, apenas quatro estudos baseados em NHANES eram publicados anualmente, com esse número saltando para 190 em 2024. Dr. Matt Spick, coautor do estudo, comentou:
“Observamos um aumento no número de artigos que parecem científicos, mas não sustentam um exame crítico.”
(“We’ve seen a surge in papers that look scientific but don’t hold up under scrutiny.”)— Dr. Matt Spick, Coautor, Universidade de Surrey
O estudo também expôs práticas questionáveis, como a “pesquisa de dados” e a alteração de perguntas de pesquisa após a visualização dos resultados.
Tulsi Suchak, autora principal do estudo, expressou a esperança de que reformas simples possam ajudar a proteger a integridade da publicação científica:
“Estamos pedindo por verificações sensatas que incluem ser transparente sobre como os dados são usados.”
(“We’re asking for some common-sense checks.”)— Tulsi Suchak, Pesquisadora de Pós-Graduação, Universidade de Surrey
As recomendações incluem uso transparente dos dados disponíveis e a aplicação de números de identificação exclusivos para rastrear como os conjuntos de dados abertos são utilizados. Com isso, a pesquisa científica poderá usufruir das vantagens das tecnologias emergentes sem comprometer sua validade.
Fonte: (TechXplore – Machine Learning & AI)