O avanço em machine learning continua a expandir os limites da inteligência artificial (IA), conforme novas pesquisas demonstram inovações significativas na análise de vídeos longos. O recente desenvolvimento do agente multimodal VideoMind pela Universidade Politécnica de Hong Kong oferece um novo paradigma para o raciocínio em vídeos.
Contexto da pesquisa
A compreensão de vídeos longos representa um desafio para os modelos de IA atuais devido à complexidade temporal e à quantidade de informações que eles contêm. A pesquisa busca não apenas identificar objetos, mas também entender suas interações ao longo do tempo.
Método proposto
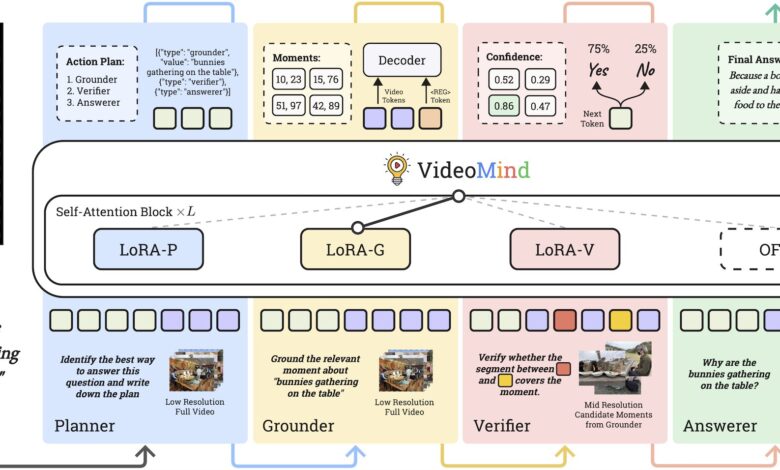
O VideoMind utiliza uma estratégia inovadora chamada de Chain-of-Low-Rank Adaptation (LoRA) para otimizar o desempenho sem a necessidade de re-treinamento completo do modelo. Esta abordagem permite que quatro adaptadores LoRA específicos de função sejam ativados dinamicamente durante a inferência, permitindo que o modelo execute várias tarefas sem a sobrecarga de múltiplos modelos.
A arquitetura do modelo é baseada em um fluxo de trabalho que simula o raciocínio humano, incorporando quatro funções principais: o Planejador, o Grounder, o Validador e o Respondedor. Cada função desempenha um papel crucial, desde a coordenação até a validação da precisão das informações.
Resultados e impacto
O desempenho do VideoMind foi avaliado em 14 benchmarks variados, comparando-o a outros modelos avançados como GPT-4o e Gemini 1.5 Pro. Os resultados indicam que o VideoMind superou significativamente seus concorrentes em tarefas desafiadoras envolvendo vídeos com uma média de 27 minutos. Mesmo em sua versão com 2 bilhões de parâmetros, o modelo demonstrou desempenho comparável ao de modelos maiores de 7 bilhões de parâmetros.
“O VideoMind não só supera as limitações de desempenho de modelos de IA na análise de vídeos, mas também serve como uma estrutura de raciocínio multimodal modular e escalável.”
(“VideoMind not only overcomes the performance limitations of AI models in video processing, but also serves as a modular, scalable and interpretable multimodal reasoning framework.”)— Prof. Changwen Chen, Professor, Universidade Politécnica de Hong Kong
As inovações trazidas pelo VideoMind proporcionam um baixo custo tecnológico e reduzem o consumo excessivo de energia, abrindo novas possibilidades para aplicações em vigilância inteligente, análise de vídeos esportivos e motores de busca de vídeos.
Fonte: (TechXplore – Machine Learning & AI)