São Paulo — InkDesign News — O aprimoramento de sistemas de reconhecimento de fala para línguas e sotaques sub-representados é um desafio significativo em machine learning. Um novo estudo apresenta uma abordagem inovadora para adaptar modelos a sotaques africanos.
Arquitetura de modelo
O modelo proposto, denominado AccentFold, foi desenvolvido por pesquisadores da Universidade de Lagos e utiliza o modelo pré-treinado XLSR como base. A arquitetura integra três cabeçotes: um para reconhecimento de fala (ASR), um para classificação de sotaque e um para classificação de domínio. Em vez de depender apenas de rotulagem explícita, o modelo aprende a partir de embeddings de sotaque, que capturam relações linguísticas complexas.
Treinamento e otimização
Os pesquisadores realizaram o treinamento utilizando a base de dados AfriSpeech 200, que contém mais de 200 horas de áudio e 120 sotaques africanos. A estratégia de treinamento adotada foi a aprendizagem multitarefa, que permite que o modelo aprenda a realizar diversas tarefas simultaneamente. Isso resulta em melhor representação de sotaques, já que a classificação de sotaques ajuda o modelo a reconhecer variações na fala.
Os autores afirmam que “essa abordagem garante que o modelo generalize para sotaques nunca vistos antes” (“this approach ensures that the model generalizes to accents it has never seen before”)— Oladimeji Owodunni, Pesquisador, Universidade de Lagos.
Resultados e métricas
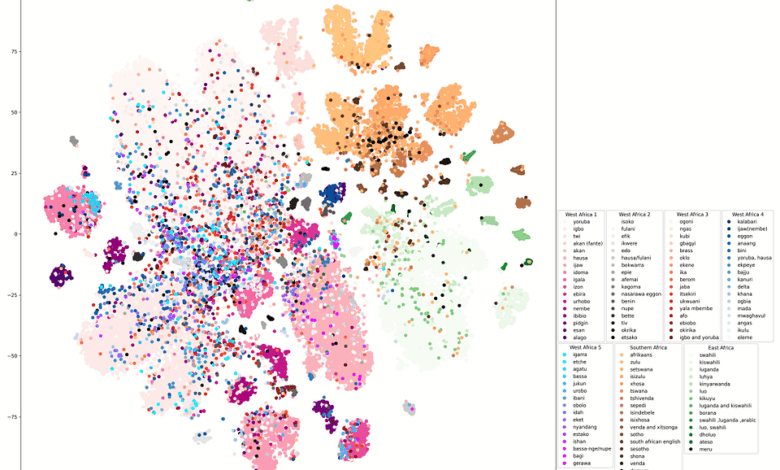
O desempenho do AccentFold foi avaliado utilizando um conjunto de 41 sotaques não vistos durante o treinamento, onde se observou uma melhora significativa na taxa de erro de palavras (WER). Em comparação com métodos tradicionais de seleção aleatória e geográfica, o AccentFold reduziu a WER em 3,5% de forma absoluta. Esta eficiência sugere que “a similaridade de embeddings é mais útil do que a proximidade geográfica” (“embedding similarity is more helpful than geographical proximity”)— Oladimeji Owodunni, Pesquisador, Universidade de Lagos.
Além disso, foi observado que aumentar o número de sotaques em treinamento melhorou resultados, mas a eficiência começou a estagnar após 25 sotaques. Isso indica que a qualidade dos dados selecionados é mais crucial do que a quantidade disponível.
Com a promessa de unir sotaques diversos e melhorar a qualidade de sistemas de ASR, o AccentFold oferece uma base para futuras inovações em reconhecimento de fala, especialmente em cenários de baixa disponibilidade de dados. As aplicações práticas dessa tecnologia podem se estender a serviços de tradução e interfaces de voz personalizadas para diferentes regiões.
Fonte: (Towards Data Science – AI, ML & Deep Learning)