Machine learning identifica padrões de alimentação para saúde preventiva
São Paulo — InkDesign News — Uma pesquisa recente explora como machine learning pode ser aplicado ao estudo dos hábitos alimentares, usando um algoritmo chamado Modified Dynamic Time Warping (MDTW) para identificar padrões temporais, indo além do conteúdo nutricional e focando em quando e com que frequência as pessoas comem.
Arquitetura de modelo
O algoritmo MDTW foi desenvolvido para superar limitações das métricas tradicionais, como a distância Euclidiana e o Dynamic Time Warping clássico, que não lidam bem com irregularidades na frequência e no horário das refeições. MDTW incorpora fatores temporais, penalizando diferenças tanto no conteúdo nutricional quanto no tempo entre os eventos alimentares.
Uma característica importante é a capacidade do MDTW de trabalhar com sequências multidimensionais, considerando nutrientes variados e tempos desiguais, além de permitir correspondências com eventos ausentes, o que reflete situações reais como pular refeições.
“MDTW é projetado para justamente esse tipo de desalinhamento temporal e variabilidade comportamental, permitindo um alinhamento flexível enquanto penaliza discrepâncias nos nutrientes e na temporização das refeições.”
(“MDTW is designed for exactly this kind of temporal misalignment and behavioral variability, allowing flexible alignment while penalizing mismatches in both nutrient content and meal timing.”)— Nitin Khanna et al., Pesquisa IEEE GlobalSIP 2017
Treinamento e otimização
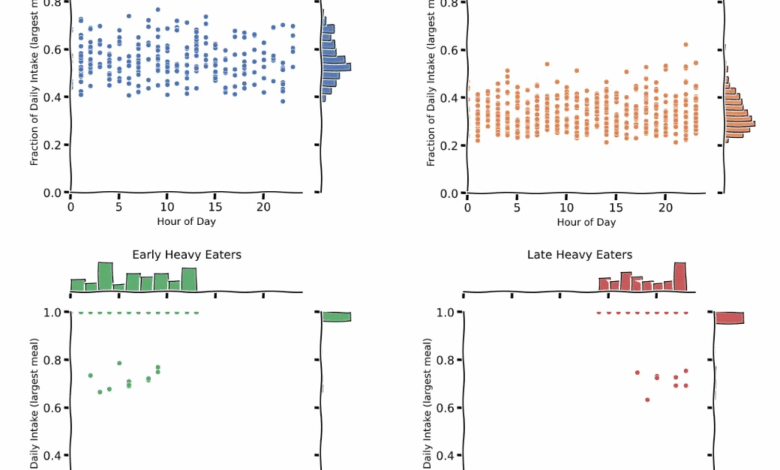
Foi implementada a distância MDTW em Python, com uso de programação dinâmica para calcular matrizes de custo local e global entre sequências de eventos alimentares. Para avaliação prática, foram gerados dados sintéticos simulando perfis de alimentação distintos, como “Frequentes Pequenas Refeições” e “Comedores Noturnos Pesados”. Com essa base, foi construída uma matriz de distância simétrica, possibilitando a aplicação de um algoritmo de clustering, o K-Medoids.
A escolha do número ideal de clusters foi feita com base em duas métricas típicas de clustering: o Método do Cotovelo e a Pontuação de Silhueta. Ambas indicaram quatro clusters como o ponto ótimo, correspondendo a padrões alimentares distintos e interpretáveis.
“O método Elbow e a pontuação de Silhueta sugerem que 4 clusters oferecem um equilíbrio entre complexidade do modelo e qualidade do agrupamento.”
(“The Elbow method and silhouette score suggest that 4 clusters provide a good balance between model complexity and clustering quality.”)— Pesquisador responsável pela implementação
Resultados e métricas
A análise dos clusters revelou perfis característicos: desde pessoas que apresentam padrões irregulares, passando por indivíduos que fazem refeições frequentes e leves, até grupos que concentram quase toda a ingestão calórica em uma única refeição, seja pela manhã ou à noite. Essas descobertas destacam a capacidade do MDTW em capturar nuances comportamentais temporais, que se perderiam em análises tradicionais focadas exclusivamente na quantidade ou qualidade dos alimentos.
O custo computacional do MDTW é maior que o DTW clássico, devido à consideração adicional de penalidades temporais e correspondências vazias, mas isso é compensado pelo ganho na interpretação dos dados e aplicabilidade em contextos reais, como monitoramento personalizado de saúde.
“Este trabalho demonstra que métricas de distância especializadas podem revelar padrões sutis que outras técnicas não capturam, abrindo novas possibilidades para monitoramento personalizado da saúde.”
(“This work demonstrates that specialized distance metrics can reveal subtle patterns that other techniques miss, opening new possibilities for personalized health monitoring.”)— Autor da pesquisa
As próximas etapas previstas incluem testes com dados reais de ingestão alimentar e a incorporação de múltiplas dimensões nutricionais para refinar ainda mais o modelo. O uso de MDTW pode também ser estendido para outras áreas onde o machine learning com dados temporais desiguais é necessário, como no monitoramento de condições crônicas baseadas em comportamentos diários.
O código-fonte completo da implementação está disponível no GitHub para que pesquisadores possam explorar e colaborar.
Fonte: (Towards Data Science – AI, ML & Deep Learning)