LLMs estimam desempenho com base em modelos menores da mesma família
São Paulo — InkDesign News —
A pesquisa sobre machine learning realizada pelo MIT e pelo MIT-IBM Watson AI Lab apresenta inovações significativas na estimativa de desempenho de modelos de linguagem. O foco está em maximizar a eficácia sob restrições orçamentárias, um dilema frequentemente enfrentado por desenvolvedores de inteligência artificial (AI).
Contexto da pesquisa
O treinamento de modelos de linguagem grandes (LLMs) pode custar milhões de dólares, levando os pesquisadores a optarem por modelos menores para prever o desempenho de modelos-alvo maiores. O resultado é uma série de leis de escalonamento que aproximam a performance de LLMs, facilitando decisões estratégicas no desenvolvimento.
Método proposto
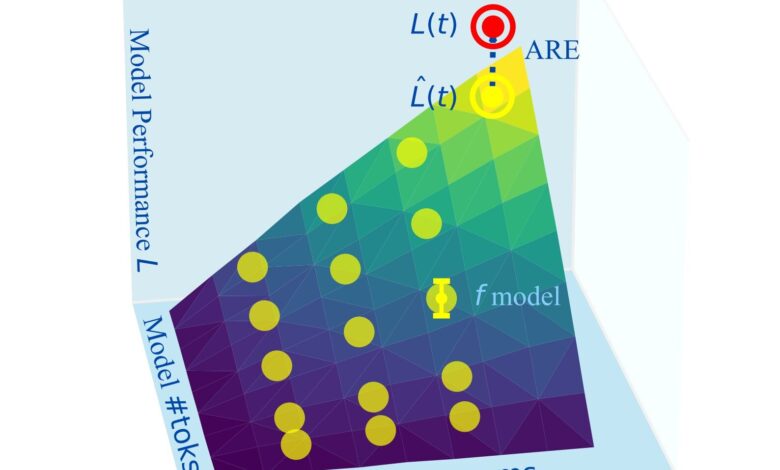
Os pesquisadores coletaram dados de 40 famílias de modelos, incluindo Pythia, OPT, OLMO, LLaMA e outros, totalizando 485 modelos únicos e 1,9 milhões de métricas de desempenho. Utilizando essas informações, foram ajustadas mais de 1.000 leis de escalonamento. As métricas de erro absoluto relativo (ARE) foram empregadas para comparar a precisão das previsões.
“Decidir um orçamento computacional e a precisão do modelo alvo é fundamental. Um ARE de 4% representa a melhor precisão esperada”
(“Critical to decide on a compute budget and target model accuracy. An ARE of 4% is about the best achievable accuracy one could expect”)— Leshem Choshen, Pesquisador, MIT-IBM Watson AI Lab
Resultados e impacto
Os pesquisadores perceberam que modelos menores, mesmo com treinamento parcial, mantêm previsões confiáveis. Ao incluir checkpoints intermediários, as leis de escalonamento tornaram-se mais robustas. Surpreendentemente, a variação observada entre diferentes famílias de modelos foi maior do que o esperado. A pesquisa também sugere que as leis de escalonamento podem prever o desempenho de modelos menores a partir de grandes modelos.
“Se os modelos pequenos são realmente diferentes, deveriam apresentar comportamentos distintos, e isso não ocorreu”
(“If they’re totally different, they should have shown totally different behavior, and they don’t.”)— Jacob Andreas, Professor Associado, MIT
As implicações são vastas, permitindo que desenvolvedores e pesquisadores, independentemente de seus recursos, compreendam e implementem leis de escalonamento eficazes. O próximo passo é explorar as leis de escalonamento em tempo de inferência, ampliando ainda mais as contribuições para o campo.
Fonte: (TechXplore – Machine Learning & AI)