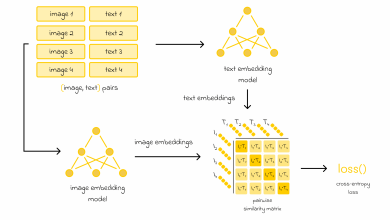
Scikit-learn simplifica seleção passo a passo em machine learning

São Paulo — InkDesign News — O uso de machine learning para modelagem preditiva é um passo crucial na análise de dados, permitindo que empresas e pesquisadores façam previsões mais precisas e informadas.
Arquitetura de modelo
O modelo de regressão linear assume uma relação linear entre a variável resposta e as covariáveis. No contexto de um conjunto de dados com numerosas variáveis preditoras, é essencial selecionar de forma eficiente quais delas serão incluídas no modelo final.
“A redução do número de variáveis em um modelo de regressão não é apenas um exercício técnico; é uma escolha estratégica que deve ser guiada pelos objetivos da análise.”
(“Reducing the number of variables in a regression model is not only a technical exercise; it is a strategic choice that must be guided by the objectives of the analysis.”)— Especialista em Estatística, Instituição Educacional
Treinamento e otimização
No processo de modelagem, é importante considerar a multicolinearidade e o risco de previsão. A aplicação de critérios como o AIC e BIC pode ajudar a determinar a melhor configuração de variáveis. Esses critérios penalizam a complexidade do modelo, buscando um equilíbrio entre a qualidade da previsão e o número de parâmetros.
“O desafio depende do propósito da análise. O modelo deve fornecer estimativas precisas dos coeficientes ou deve maximizar a acurácia preditiva?”
(“The challenge depends on the purpose of the analysis. Should the model provide precise estimates of the coefficients? Should it maximize predictive accuracy?”)— Pesquisador, Centro de Dados Avançados
Resultados e métricas
Utilizando o Critério de Informações de Akaike (AIC) e o Critério de Informações Bayesiano (BIC), os pesquisadores podem comparar múltiplos modelos e selecionar aquele com a melhor performance preditiva. Métodos de validação cruzada, como o k-fold, são integrais para avaliar a eficácia do modelo, otimizando o tempo de treinamento e melhorando a generalização.
“Escolher o modelo que minimiza o BIC equivale a escolher o modelo com a maior probabilidade posterior, dada a informação disponível.”
(“Choosing the model that minimizes the BIC is equivalent to choosing the model with the highest posterior probability given the data.”)— Doutorando em Ciências de Dados, Universidade de São Paulo
As aplicações práticas destas abordagens de modelagem podem levar a melhores decisões empresariais e desenvolvimentos em áreas como análise de risco, marketing preditivo e identificação de padrões de comportamento em grandes bases de dados. Com a contínua evolução no campo do deep learning, as oportunidades para a inovação são vastas e promissoras.
Fonte: (Towards Data Science – AI, ML & Deep Learning)