Aprimoramento de modelos de linguagem com reinforcement learning
São Paulo — InkDesign News — Recentemente, pesquisadores têm explorado técnicas de machine learning para aprimorar modelos de linguagem menores através do aprendizado por reforço, estabelecendo um novo paradigma no treinamento de algoritmos.
Arquitetura de modelo
Os modelos de linguagem pequenos, como os com menos de 1 bilhão de parâmetros, enfrentam desafios significativos devido à sua limitação em conhecimento do mundo real, o que compromete sua capacidade de raciocínio em tarefas lógicas complexas. Um estudo recente mencionou que “Modelos pequenos simplesmente não possuem o conhecimento do mundo que modelos grandes têm. Isso faz com que um modelo com menos de 1B de parâmetros careça do ‘senso comum’ necessário para raciocinar através de tarefas lógicas complexas.” (“Small models simply do not have the world knowledge that large models do. This makes < 1B parameter model lack the ‘common sense’ to easily reason through complex logical tasks.”) — Autor, Pesquisador.
Com a introdução do algoritmo de Group Relative Policy Optimization (GRPO), os pesquisadores estão agora usando uma técnica chamada aprendizado por reforço com recompensas verificáveis (RLVR). O RLVR se diferencia do aprendizado por reforço com feedback humano (RLHF), ao focar em ensinamentos que garantem respostas corretas baseadas em verificações objetivas, especialmente úteis para tarefas matemáticas e lógicas.
Treinamento e otimização
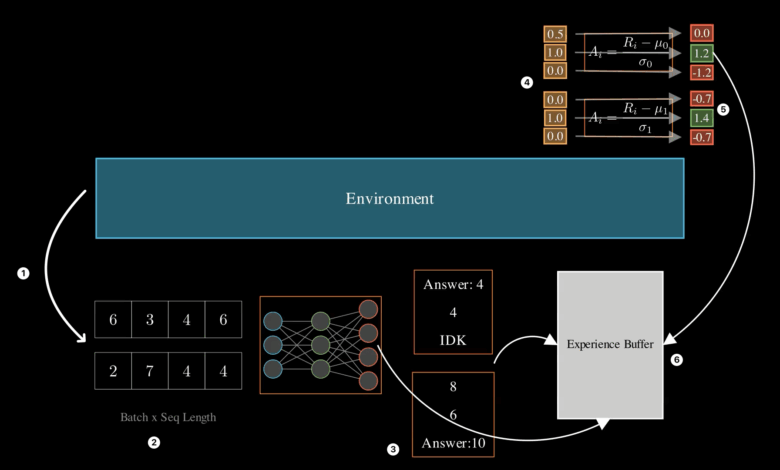
O treinamento desses modelos envolve a coleta de experiências, onde o modelo gera respostas para perguntas lógicas e é recompensado com base na correção de suas respostas. Com isso, as vantagens são calculadas para otimizar as respostas geradas. Durante suas experiências, o modelo acumula resultados e aprende a melhorar suas respostas em iterações subsequentes. Ao abordar os desafios associados aos pequenos modelos, cabe salientar que “é necessário ensinar ao modelo o comportamento que você deseja treinar usando a afinação supervisionada.” (“the recommended approach is to first teach the model the behavior you want to train using supervised fine-tuning.”) — Autor, Pesquisador.
O grupo estimulou a geração de tarefas usando um repositório específico chamado reasoning-gym, que engloba vários tipos de problemas lógicos, aumentando as opções disponíveis para treinamento. A aplicação de técnicas como LORA (Low-Rank Adaptation) também otimizou o treinamento, permitindo um ajuste eficiente das capacidades do modelo sem alterar significativamente seu funcionamento original.
Resultados e métricas
Os resultados do treinamento indicaram que modelos de linguagem pequenos como o SmolLM-135M-Instruct, após a fine-tuning supervisionada, alcançaram taxas de precisão superiores a 60%, demonstrando um avanço notável de 20% em comparação aos testes iniciais. A recompensas obtidas estavam alinhadas com a diversidade de respostas, indicando um treinamento saudável e contínuo no uso de algoritmos de aprendizado por reforço. Uma análise detalhada trouxe à luz que “a geração de respostas diversas é a chave para possibilitar o aprendizado por reforço.” (“Generating diverse responses IS KEY to making RL possible.”) — Autor, Pesquisador.
As implicações práticas desse avanço em machine learning são promissoras, com o potencial de aprimorar a interpretação de dados e a capacidade de resolver problemas complexos, ao mesmo tempo que incentiva futuros pesquisas em algoritmos mais escaláveis e generalizáveis.
Fonte: (Towards Data Science – AI, ML & Deep Learning)