Modelo de linguagem visual cria planos de inspeção automatizada
Pesquisas recentes em machine learning e inteligência artificial têm possibilitado o avanço na automação de tarefas complexas, como a inspeção de ambientes. Um novo estudo explora o uso de modelos de linguagem visual para a geração de planos de inspeção automatizados com precisão.
Contexto da pesquisa
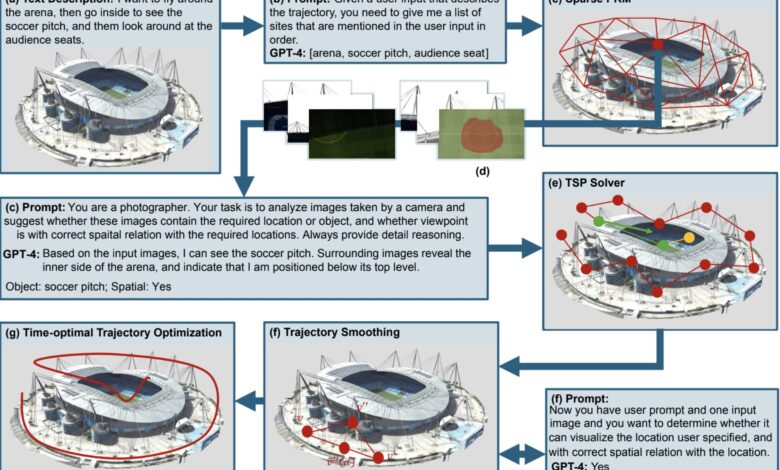
A automação em inspeções de infraestruturas perigosas, como túneis e usinas, ainda é um desafio, com muitos processos realizados por humanos. Pesquisadores da Universidade Purdue e da LightSpeed Studios desenvolveram um modelo computacional que gera planos de inspeção baseados em descrições escritas, utilizando modelos de linguagem visual (VLM).
Método proposto
O modelo apresentado é um pipeline sem treinamento que utiliza um VLM pré-treinado (ex.: GPT-4o) para interpretar alvos de inspeção descritos em linguagem natural e imagens relevantes. O modelo avalia pontos de vista candidatos com base em alinhamento semântico. Para a geração de trajetórias de inspeção, eles resolvem um problema de otimização de Viajante de Comércio (TSP) usando Programação Inteira Mista, considerando relevância semântica, ordem espacial e restrições de localização.
“Propomos um pipeline sem treinamento que utiliza um VLM pré-treinado para interpretar alvos de inspeção descritos em linguagem natural junto com imagens relevantes.”
(“We propose a training-free pipeline that uses a pre-trained VLM to interpret inspection targets described in natural language along with relevant images.”)— Xingpeng Sun, Primeiro Autor, Universidade Purdue
Resultados e impacto
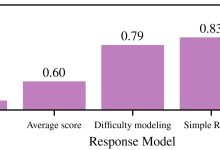
Os pesquisadores avaliaram a geração de planos e obtiveram resultados promissores, com o modelo delineando trajetórias suaves e pontos de vista ideais, prevendo relações espaciais com uma acurácia superior a 90%. O TSP ajudou a otimizar as trajetórias de inspeção, aprimorando a precisão no planejamento de rotas para robôs em ambientes 3D.
“Nossas descobertas revelam que VLMs como o GPT-4o exibem fortes capacidades de raciocínio espacial ao interpretar imagens multivista.”
(“Our findings also reveal that state-of-the-art VLMs, such as GPT-4o, exhibit strong spatial reasoning capabilities when interpreting multi-view images.”)— Xingpeng Sun, Primeiro Autor, Universidade Purdue
Os próximos passos incluem testar o modelo em cenários mais complexos e integrar feedback visual ativo, visando deploys físicos em inspeções em tempo real.
Fonte: (TechXplore – Machine Learning & AI)